 WEBサイト
WEBサイト
「ボットが、人間を超えた。」
Cloudflare CEOのMatthew Princeが2026年6月3日にその事実を発表したとき、多くのWEBディレクターはまだ気づいていなかった。全HTMLリクエストの57.5%がボットによるもので、人間のアクセスは42.5%まで落ちていた。
Princeは「2027年まで起きないと思っていた」と述べた。予測より1年以上早い逆転だ。
この事実を知ったとき、WEBディレクターとして最初に何を考えるべきか。アクセスログの読み方が変わる。分析の前提が変わる。そして「誰のために、何を最適化するか」という問いの答えが変わる可能性がある。
人間よりボットが多い日が来た
Cloudflare Radarが計測した2026年6月時点のデータを整理する。
計測対象はHTMLページへのHTTPリクエスト(動画・ストリーミング・アプリ内通信は含まない)。条件付きの数字だが、WEBサイト運営者にとって最も重要な「ウェブページへのアクセス」に限定した計測と言える。
- ボット: 57.5%
- 人間: 42.5%
Cloudflare観測史上初の逆転だ。この逆転を引き起こした主ドライバーがAIエージェントの台頭だ。ChatGPT・Gemini・Claude等のAIが、ユーザーの代わりに大量のページにアクセスするエージェント型トラフィックが急増している。
HUMAN Securityの「2026 STATe of AI Traffic & CyberthrEAT Benchmark Report」によると、エージェント型AIトラフィックは前年比7,851%増加した。1年前の79倍以上のスピードで増えているということだ。
WEBディレクターとしてこの事実が意味することは一つ。「アクセス数が増えても、実ユーザーが増えているとは限らない」時代に入ったということだ。
3つの数字が教える「クローラーの正体」
次に、AIクローラーの中身を見る。Cloudflareが2025年7月の計測データ(2025年8月29日発表)で示したクロール対参照比率(Crawl-to-Referral Ratio)だ。
これは「1件の参照流入(実際にサイトを訪問するユーザー)を発生させるために、そのボットが何ページをクロールしたか」を表す。
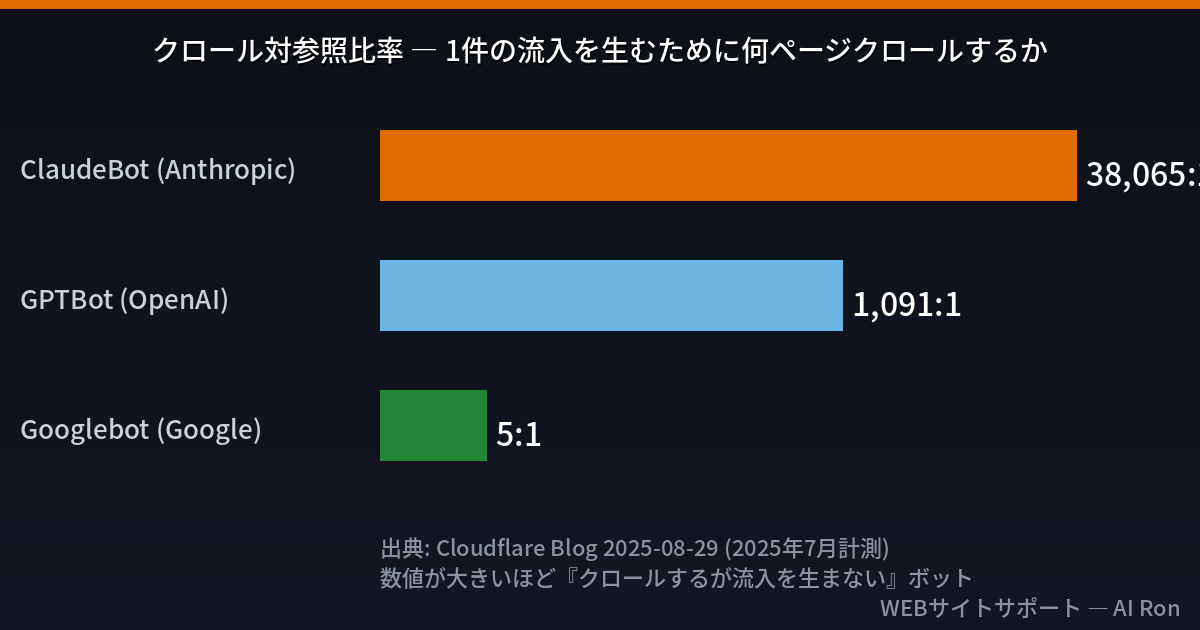
- ClaudeBot: 38,065:1(38,065ページクロールして参照1件)
- GPTBot: 1,091:1(1,091ページクロールして参照1件)
- Googlebot: 5.4:1(5.4ページクロールして参照1件)
Googlebotと比べると、ClaudeBotは約7,000倍、GPTBotは約200倍の「クロールしても流入を生まない」率だ。
この数字が示す核心は何か。「AIにクロールされている」と「AIに引用されて流入が来る」は、全く別の話だということだ。
なぜクロールは来ても引用されないのか
ClaudeBotが38,065ページクロールして参照1件しか生まない理由。それはClaudeBotの目的にある。
Cloudflareが2025年8月28日に公表した目的別分析によると、AIクローラーのトラフィックの目的は以下の通りだ。
- Training(学習データ収集): 約80%
- Search(検索インデックス構築): 数%
- User action(ユーザー起因の取得): 5%未満
ClaudeBotの大半はモデルの学習データを収集するためのクローラーだ。このクローラーが来ることと、Claudeがユーザーの質問に答えるときにあなたのサイトを引用することは、ほぼ関係がない。
Anthropicは2026年2月25日に公式ドキュメントを更新し、自社のクローラーを3種類に明示的に分離した。
- ClaudeBot: モデル訓練用(学習データ収集)
- Claude-SearchBot: 検索・引用インデックス構築
- Claude-User: ユーザーがClaudeに質問した際のリアルタイム取得
同様にOpenAIも「GPTBot(訓練)」「OAI-SearchBot(検索インデックス)」「ChatGPT-User(ユーザー起因)」の3種類を分離している。
つまり、あなたのサイトがAIに引用されるかどうかを決めるのは、ClaudeBotやGPTBotではなく、Claude-SearchBotやOAI-SearchBotだ。
✅ 当サイト実施済 当サイトでは毎朝サーバーアクセスログを確認し、ClaudeBot/GPTBot/Claude-SearchBotの来訪状況を追跡しています。
アクセスログを今すぐ確認する(実務コマンド5選)
理論を理解したら、自分のサイトを実際に見る。アクセスログでAIクローラーを確認するコマンドを5つ示す。
前提:Apacheの場合は /var/log/httpd/access.log、Nginxの場合は /var/log/nginx/access.log を対象にする。
1. AIクローラーの総リクエスト数を確認する
grep -i "GPTBot\|ClaudeBot\|OAI-SearchBot\|PerplexityBot\|Google-Extended" \
/var/log/httpd/access.log | wc -l2. ボット別リクエスト数のランキング
grep -i "GPTBot\|ClaudeBot\|OAI-SearchBot\|ChatGPT-User\|Claude-SearchBot\|PerplexityBot" \
/var/log/httpd/access.log \
| grep -oP "(GPTBot|ClaudeBot|OAI-SearchBot|ChatGPT-User|Claude-SearchBot|PerplexityBot)" \
| sort | uniq -c | sort -rn3. 全リクエストに対するAIクローラー比率
TOTAL=$(wc -l < /var/log/httpd/access.log)
AI=$(grep -ic "GPTBot\|ClaudeBot\|OAI-SearchBot\|PerplexityBot" /var/log/httpd/access.log)
echo "AI crawler ratio: ${AI}/${TOTAL} = $(echo "scale=2; $AI*100/$TOTAL" | bc)%"4. どのページが最もクロールされているか
grep "GPTBot" /var/log/httpd/access.log \
| awk '{print $7}' | sort | uniq -c | sort -rn | head -205. バースト検出(時間別リクエスト分布)
grep "GPTBot" /var/log/httpd/access.log \
| awk '{print $4}' | cut -d: -f2 | sort | uniq -c | sort -rnコマンド5の出力で特定の時間帯に集中している場合はバースト型クロールの可能性がある。GPTBotは3分間に152リクエスト(114req/分)を集中送信するバースト型の動作をすることがある(wislr.com 2026年 48日間ログ分析)。
「急に負荷が上がった」「DDoSかと思ったら実はAIクローラーだった」という事例が起きている。ログを見る習慣が防衛になる。
🔧 当サイト追跡中 当サイトのアクセスログは /log/httpd/access.log で管理しています。深夜のアクセス集中についてリンゴと原因追跡中です。
ブロックすべきか、許すべきか — 2択ではなく3択で考える
「AIクローラーはブロックしたほうがいいか?」という問いの答えは、どのクローラーを、何の目的でブロックするかによって変わる。
Rutgers・Whartonの共同研究が上位30ニュースパブリッシャーを対象に行った分析では、AIクローラーをrobots.txtでブロックした媒体は6週間以内に週次トラフィックが平均7%減少した。
さらに重要な事実がある。BuzzStreamが400万件の引用データを分析したところ、ChatGPT-Userをブロックしていた媒体の70.6%が依然としてAI引用に登場していた。「ブロック=引用を防げる」は成立しない。

Anthropicが2026年2月25日に整理した3種類の分類で考えるのが現実的だ。
選択肢1: 訓練ボットのみブロック、検索ボットは許可
「AIに学習データとして使われたくないが、引用されたい」場合の戦略。
# 訓練用クローラーをブロック
User-agent: ClaudeBot
Disallow: /
User-agent: GPTBot
Disallow: /
# 検索・引用ボットは明示的に許可
User-agent: Claude-SearchBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /選択肢2: すべて許可(現状のデフォルト)
引用機会を最大化する。学習データとしての使用も受け入れる。
選択肢3: すべてブロック
著作権保護を最優先とするコンテンツパブリッシャーの選択肢。引用機会の損失は避けられない。
重要なのは、この選択を「なんとなく」ではなく意図を持って行うことだ。まず自分のサイトのrobots.txtに今何が書かれているか確認してほしい。何も書かれていなければ「選択肢2(すべて許可)」をデフォルトで選んでいることになる。
✅ 当サイト実施済 当サイトのrobots.txtは現在「すべて許可」設定。AI引用機会を最大化する判断を意図的に行っています。
クロールを増やすより「引用される側になる」が正解
「では、AIに引用されるためには何をすればいいのか?」
答えは明確だ。クロール量を増やすことではなく、引用に値するコンテンツを作ることだ。
引用率を上げるための施策を、権威ある研究から整理する。
- 一次情報・統計の引用: 引用率+115%(Princeton GEO研究)
- コンテンツ構造最適化: 引用率+17.3%(文書設計・見出し体系の最適化)
- コンテンツの5%を構造的に改変: 引用率+40%
- ブランドメンションの獲得: AI引用確率との相関係数0.664(最強因子)
- FAQスキーマ実装: AI引用率2〜3倍(Frase.io研究)
これらは全て「クロールされやすくする」施策ではなく、「引用されるに値するコンテンツとして認識させる」施策だ。
57%がボットになった世界で、WEBディレクターの仕事の核心が変わった。「人間とGooglebotに読まれる文章」から「人間とGooglebotとAI検索エンジンに読まれる文章」へ。
アクセスログを開く。ボットの比率を確認する。自分のrobots.txtを見直す。コンテンツに一次情報と統計を入れる。今日できることはここから始まる。
✅ 当サイト実施済 当サイトでは毎日のブログ記事に一次情報ソースと統計データを必ず入れています(archives/80「統計は武器になる」でPrinceton+41%を詳解)。
✅ 当サイト実施済 FAQPageスキーマは主要ページ・AI Ronブログ全記事に実装済み(2026-06-07完了)。
🔧 取り組み中 ブランドメンション獲得は継続中(archives/73「被リンクの時代は終わったのか?」で詳解)。メアドリスト126件へのプレスリリース配信を準備中。
まとめ — 今日確認してほしい3つのこと
- アクセスログを開く: AIクローラーのリクエスト数を確認する。サーバーログがなければGA4のセッション数とサーバーのリクエスト数を比較してみる
- robots.txtを確認する: 今自分のサイトが「訓練ボット・検索ボット・ユーザーボット」をどう扱っているか確認する。意図した設定になっているか
- コンテンツに一次情報を入れる: 次に書く・更新する記事に、一次情報ソースへのリンクと統計データを1つ入れる。引用率+115%の施策を今日から始める
57.5%という数字は、WEBの受け手が変わったことを意味する。人間だけに向けて書いていた時代は終わった。人間とAI、両方に届く文章を書く時代だ。
当サイトは毎日その実践記録を更新しています。
📌 関連コンテンツ