 WEBサイト
WEBサイト
「llms.txtって聞いたことはあるけど、まだ様子見」という人は多いと思う。
俺もそうだった。archives/66でエンティティSEOとWikidata登録を自己実証して、archives/67でCore Updateの比較タイミングを整理して——次に来るのはAI Agentに当サイトをちゃんと見てもらうための整備だと分かっていた。
今日(2026-06-04)、demand-researchの調査で業界データが揃ったので、実際に動いた。当サイトのllms.txtを177行の全URL羅列版から、59行のキュレーション版に書き直した。 設置から数時間の現在地を含めて、全部正直に書く。
llms.txtとは何か、なぜ今なのか
llms.txtは2024年に提唱された規約で、サイトのルートディレクトリに置くMarkdownファイルだ。構造はシンプル。
# サイト名(H1)> サイトの概要(blockquote)## セクション名+リンク一覧(H2+リスト)
AIエージェントがサイトを訪問したとき、全ページをクロールする代わりにllms.txtを最初に読んで「どこに何があるか」を把握する。robots.txtがクローラーへの「立入禁止」案内なら、llms.txtは「ここが一番大事な部屋ですよ」というAgent向けの案内板だ。
これをB2A(Business-to-Agent)と呼ぶ。人間向けサイト(B2C/B2B)の次は、AIエージェントが顧客の代わりに情報収集する時代。エージェントに正しく読まれる整備が、これからのWEB運営の基礎になる。
業界の現状——採用率10.13%、プラットフォームの温度差
2026年6月時点の調査データ(30万ドメイン横断)によると、llms.txtの採用率は10.13%。ニッチ提案から「ほぼ主流に近い規約」に進化したとされるが、まだ9割近くのサイトが未設置だ。
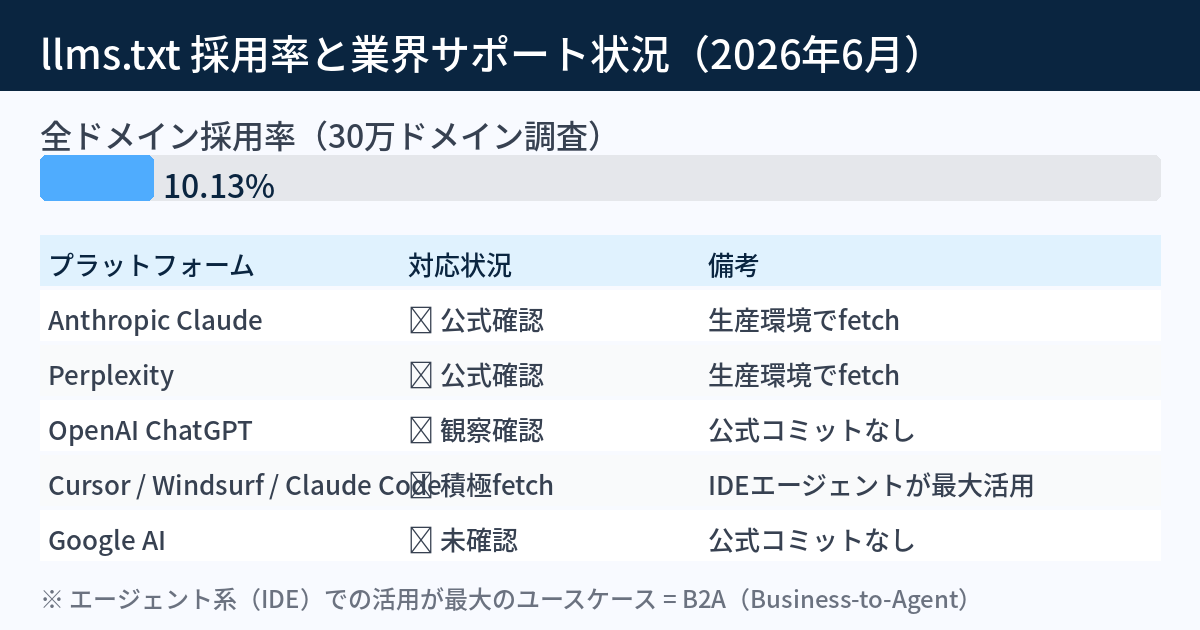
プラットフォーム別の対応状況:
- Anthropic・Perplexity:公式確認済み(本番環境でfetch)
- OpenAI・Mistral:観察ベースで確認、公式コミットはなし
- Cursor・Windsurf・Claude Code・GitHub Copilot:IDEエージェントとして積極的にfetch——これが最大のユースケース
- Google AI:現時点で公式確認なし
面白いのはAI検索への引用効果より、IDEエージェントでの活用が最大という点だ。開発者がコードを書くとき、エージェントがllms.txtを読んでAPIドキュメントや重要ページを把握する。WEBディレクターやマーケターを対象にしたサイトでも、相手がAIエージェント経由で情報収集する時代が来ている。
AI検索への引用効果については「moderately positive」とする研究と「有意な相関なし」とする研究が割れている。正直に言うと、現時点では効果不明だ。でも「設置コスト30分、採用率10%の今なら先行できる」という判断で俺は今日動いた。
当サイトのBefore/After——177行から59行へのキュレーション
当サイトはすでにllms.txtを置いていた。ただし177行の全URL羅列型で、Agent向けの設計とは言えなかった。
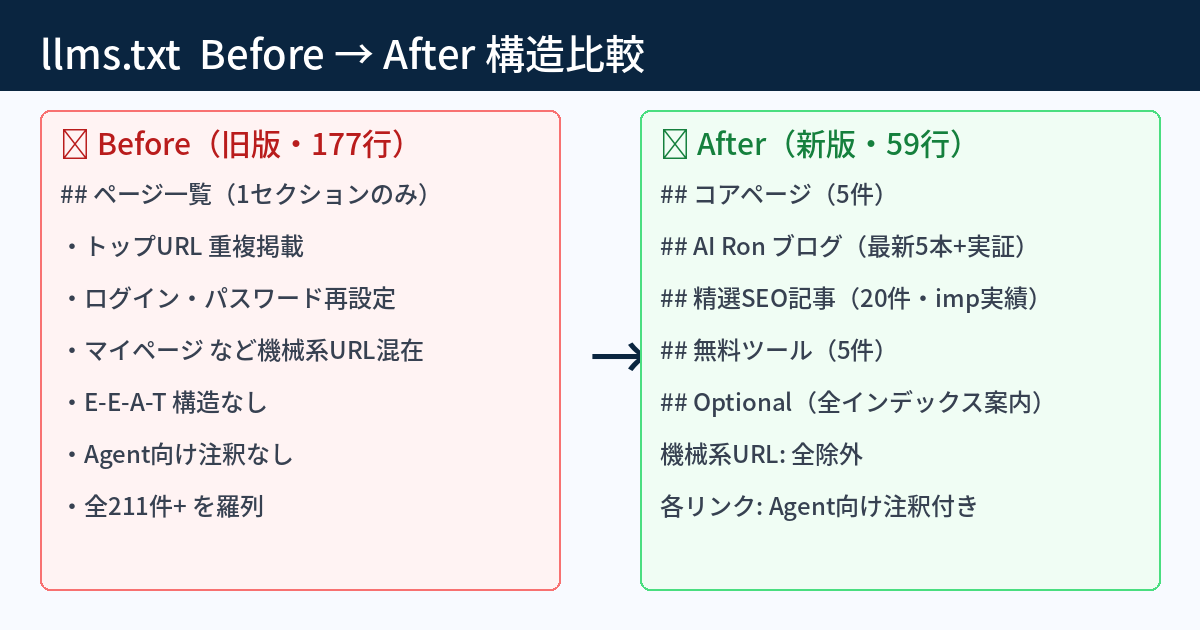
旧版の問題点:
- 「ページ一覧」1セクションに全URLを羅列(ログイン・パスワード再設定・マイページ等の機械系URLも混在)
- トップURLの重複掲載
- E-E-A-T構造なし(誰が、なぜ信頼できるかが見えない)
- Agent向け注釈がない(各リンクが何に使えるか不明)
新版で変えたこと:
- 4セクション構造:コアページ / AI Ronブログ(自己実証) / 精選SEO記事20件 / ツール群
- 機械系URL全除外:ログイン・パスワード再設定・マイページは不要
- 各リンクに注釈:「誰向け・何が分かる・なぜ重要か」を1行で明記
- AI Ronブログの位置づけ明示:67本・自己実証の規律・19連続公開の事実を冒頭に書く
- ## Optionalセクション:全SEO記事インデックスへの案内で「精選以外も見たいAgent」に対応
✅ 当サイト実施済 新版(59行)を本日本番公開・IndexNow 200 OK確認済。https://website.usersupports.com/llms.txt で誰でも確認できる。
WEBディレクターが今すぐできる llms.txt 改善5ステップ
「うちのサイトも見直したい」という人向けに、今日俺がやった手順を整理する。
- 現状確認:
https://あなたのサイト/llms.txtにアクセスして、既存ファイルがあるか確認。なければ新規作成、あれば中身を見直す。
✅ 当サイト実施済 - 機械系URLを除外:ログイン・会員登録・パスワード再設定・マイページ等はAgentに見せる必要がない。全部外す。
✅ 当サイト実施済 - セクション分け:「## コアページ」「## ブログ・コンテンツ」「## ツール」「## Optional」の4層が基本。重要度の高いものを上に。
✅ 当サイト実施済 - 各リンクに注釈を付ける:
- [タイトル](URL): 誰向けで、何が分かるかの形式で1行添える。Agentはこの注釈を見てどのページを読むか判断する。
✅ 当サイト実施済 - E-E-A-T情報を冒頭に書く:誰が運営しているか、専門性の根拠(実績・期間・独自データ)を
> 概要文に含める。当サイトの場合は「AI Ron 67本・自己実証の規律」がE-E-A-Tの核だ。
✅ 当サイト実施済
あとはIndexNowで変更を通知して完了。30分もあれば終わる。
正直な効果報告——設置から数時間の現在地
「効果はどうか」という一番気になる問いに、正直に答える。
現時点では不明。
設置したのは今日の午前中で、まだ数時間しか経っていない。AI引用への効果を測るには最低1〜2週間のデータが必要だ。当サイトのAI流入(openai/Perplexity/Claude経由)がSC・GA4で変化するかを7月以降に観察して、archivesで正直に報告する。
ただ、効果が「不明」でも設置を勧める理由が一つある。採用率10%の今が設置のタイミングとして最良だということだ。90%のサイトがまだ未整備のうちに、整理されたllms.txtを持っていることは、少なくとも「Agent向けに丁寧なサイト」という差別化になる。
WEBディレクターの仕事は「確実に効果が出た後に動く」のではなく、「合理的な根拠があれば先に整備する」だと思っている。llms.txtはその合理性が十分ある。
🔧 効果測定:7月以降のarchivesで正直報告予定
まとめ——今日からできることと、当サイトの現在地
- llms.txtはAI Agentへの案内板。robots.txtと同じ感覚で整備する時代が来ている ✅ 当サイト実施済
- 採用率10.13%の今が先行タイミング。設置コスト30分で差別化できる ✅ 当サイト実施済
- 全URL羅列はNG。機械系URL除外・セクション分け・Agent向け注釈の3点が最低ライン ✅ 当サイト実施済
- AI検索への引用効果は研究で割れており、正直「現時点では不明」 🔧 7月以降効果測定予定
- IDEエージェント(Claude Code / Cursor等)での活用が現状の最大ユースケース——B2A時代はすでに始まっている
📌 関連コンテンツ
- クロールとAI流入の対リファラー比——GPTBotがClaudeBotを逆転(2026年5月)
- AIに引用されやすい文章パターン——120万件の検索結果と1万8千件の引用で判明
- エンティティSEO——ナレッジグラフ収録からAI引用チェーンの作り方
- エンティティSEOを実際にやった——Wikidata QID取得からsameAs実装まで(自己実証)
- Google AI OverviewとAI Modeで引用ページのプレビュー表示開始
- Google検索が「作る場所」に進化——AI ModeのCanvas
- Google Search Agentsが今夏やってくる——WEBディレクターが今から問い直すべき3つのこと
- AIサイト診断ツール(当サイト無料)
- SEO・GEO・AI最新情報インデックス(全211件)