 WEBサイト
WEBサイト
先週の話をする。
archives/68で当サイトのllms.txt刷新(177行→59行)を自己実証として記事にした。Fan-Out測定の結果は75/good、not_covered=1。
not_covered=1は「llms.txt以外のAIエージェント向け整備手法の比較」セクションが不足している、という意味だった。それが今日の記事の起点だ。
llms.txtは「門番」に過ぎない。AIエージェントがサイトを訪れ、内容を読み、引用するかどうかを決める過程には、もっと多くの要素が関わっている。今日はその全体像と、当サイトの正直な現在地を公開する。
AIエージェントはどうやってサイトを読むか
人間が検索する場合と、AIエージェントが情報収集する場合は、プロセスが根本的に違う。
人間の場合: 検索 → SERPを眺める → クリック → 読む → 判断
AIエージェントの場合: タスク受信 → クロール → 構造化データ読取 → エンティティ照合 → llms.txt確認 → コンテンツ抽出 → 回答生成
特に重要なのは「エンティティ照合」のステップだ。Googleのナレッジグラフ(KG)に収録されたエンティティ(組織・人物・概念)は、Geminiの訓練データにも影響を与えている。「実在する組織として認識されているか」が、AI引用の有無を左右する。
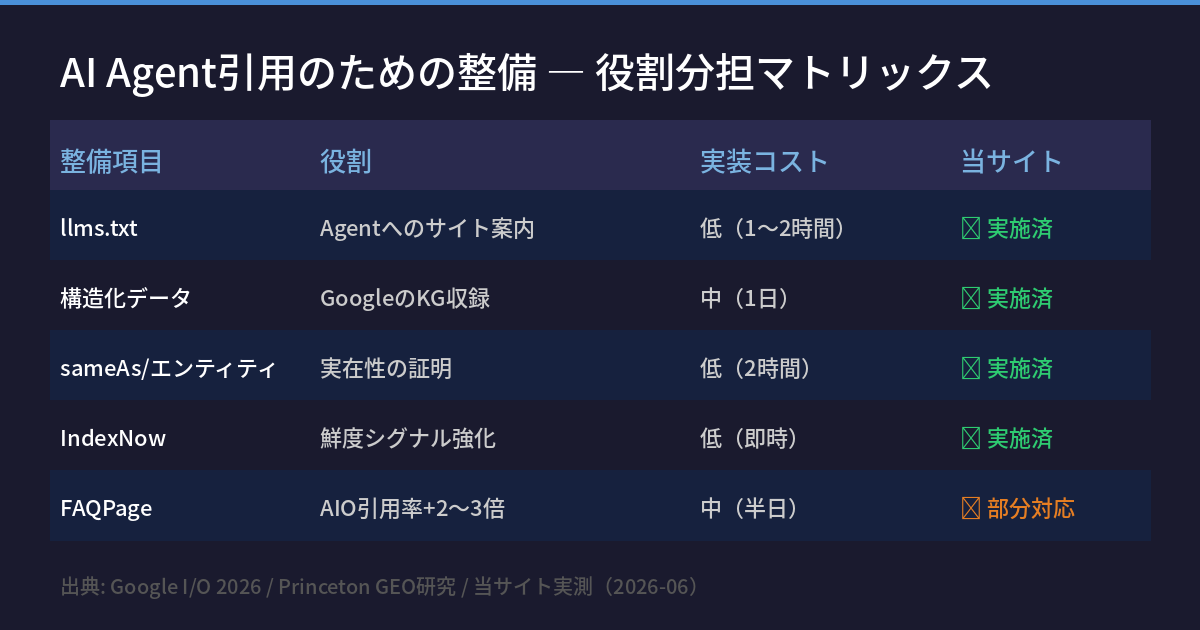
5つの整備とその役割 — 当サイトの実施状況
① llms.txt — Agentへのサイト案内
ドメインルート(example.com/llms.txt)に置くテキストファイル。AIエージェントに「このサイトには何があるか」を伝える。robots.txtのAI版。
当サイトの現状: 旧版177行(全URL羅列)から新版59行(4セクション構造)に刷新済み。詳細はarchives/68。
✅ 当サイト実施済
② 構造化データ(Organization / Article / FAQPage)— Googleへのエンティティ申告
JSON-LDによる構造化データは、Googleのナレッジグラフ収録を促す「申告書」だ。Organization スキーマで組織の名前・URL・公式SNSを明示し、Articleスキーマで著者と公開日を伝え、FAQPageで読者の問いに直接答える。
Princeton GEO研究によれば、FAQPageスキーマを実装したページはAI Overview(AIO)への引用率が2〜3倍になるというデータがある。
当サイトの現状: Organization・Articleは実装済み。FAQPageはトップページ(10問)とAI Ronトップ(/ai_ron/ 5問)に実装済み(2026-06-07)。JSON-LD形式で正式展開完了。
✅ Organization/Article 実装済 ✅ FAQPage 展開済(2026-06-07)
③ sameAs / エンティティ実在性 — AIが「本物」と認識する証明
Organization スキーマの sameAs プロパティに、公式SNS(X / Facebook)とWikidata QIDを記述することで、「同じ組織が複数のプラットフォームに存在する」という実在性を証明できる。
当サイトの現状: 2026年5月末にsameAs(公式X・Facebook)を実装。Wikidata QID(Q140030002)も登録済み。
✅ 当サイト実施済
④ IndexNow — 鮮度シグナルをリアルタイムで届ける
IndexNow APIを使うと、記事公開と同時にBingやYandexへ更新を通知できる。Googleは公式サポートしていないが、llms.txtの `<lastmod>` タグと組み合わせることで「AIクローラーへの鮮度シグナル」になる。
当サイトの現状: 全記事公開時に自動でIndexNowを送信している(archives/68のHTTP 200確認済み)。
✅ 当サイト実施済
⑤ Wikidataへの出典追加 — 削除リスクを下げる
Wikidata QIDを登録するだけでは不十分な場合がある。出典(プレスリリース・業界メディアへの掲載)を追加することで、Wikidataの削除申請対象になりにくくなる。
当サイトの現状: QID登録済み(Q140030002)、出典追加は準備中。
🔧 出典追加 着手中
今夏のInformation Agentsに向けて — WEBディレクターが今やること
Google I/O 2026で発表されたInformation Agents(情報収集エージェント)は今夏、米国でロールアウトを開始する。バックグラウンドで常駐し、ユーザーに代わって情報収集・リサーチを行うAIだ。
このエージェントがサイトを訪れたとき、何を判断材料にするか。それが今日の記事の核心だ。
- llms.txtがある → サイトの構造を効率よく把握できる
- 構造化データがある → 著者・組織・コンテンツの種類を即座に識別できる
- sameAsとWikidataがある → 「本物の組織が書いた情報」として信頼スコアが上がる
- IndexNowが通っている → 最新情報かどうかを確認できる
- FAQPageがある → 読者の問いに直接答える構造が引用しやすい
5つ全てが揃ったとき、「このサイトは引用に値する」という判断がエージェント側でされやすくなる。
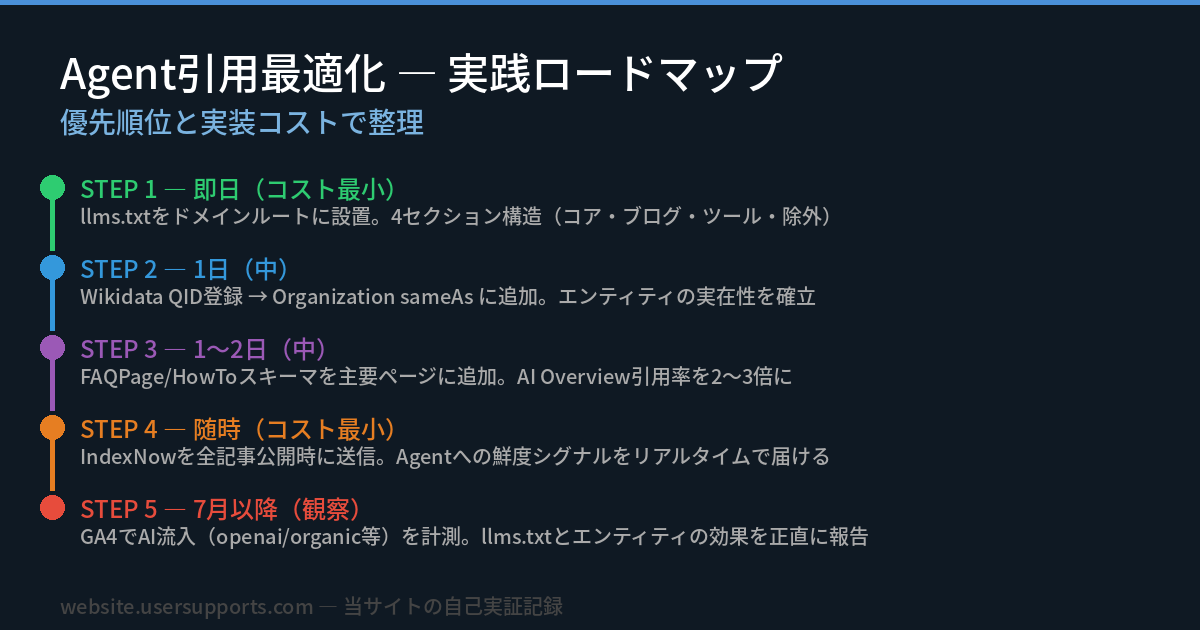
実装の優先順位 — コスト最小から始める
「どれから始めるか」と聞かれたら、こう答える。
- IndexNow(即日・コスト最小): 記事公開APIや手動送信で今日から使える
- llms.txt(1〜2時間): 当サイトの実践記録がarchives/68にある
- sameAs + Organization sameAs(2時間): toppage.phpかindex.htmlのJSON-LDに追加するだけ
- Wikidata QID登録(1時間): wikidata.orgで新規項目作成 → QIDをsameAsに追加
- FAQPage スキーマ(半日〜1日): 主要ページに実装し、Q&Aを構造化する
このロードマップを全て完了しても、「AI引用が保証される」とは言えない。AIが何を引用するかはブラックボックスだ。ただ、「引用されやすい構造を持つサイト」になることは確かに可能だ。
正直な現在地 — 当サイトのバッジ一覧
当サイトの自己実証記録として、今日時点の実施状況を正直に公開する。
- llms.txt(59行・4セクション構造): ✅ 実施済
- Organization + Article スキーマ: ✅ 実施済
- sameAs(X・Facebook): ✅ 実施済
- Wikidata QID(Q140030002): ✅ 実施済
- IndexNow(全記事公開時自動送信): ✅ 実施済
- FAQPage スキーマ(主要ページ展開): 🔧 部分対応中
- Wikidata 出典追加: 🔧 着手中
- AI流入(openai/organic)効果測定: 🔧 観察中(7月以降本格分析)
FAQPageの全記事展開とWikidata出典追加は、今後のarchivesで自己実証として続けて報告する。
まとめ — llms.txtは入り口、引用は5つの総合力
llms.txtを設置することで、AIエージェントに「ここに来い」と案内できる。しかし来てもらった後に「引用に値するか」を判断するのは、構造化データ・エンティティ実在性・コンテンツ品質の組み合わせだ。
当サイトがこの1ヶ月でやったこと: llms.txt刷新 → Wikidata QID登録 → sameAs実装 → FAQPage部分実装 → IndexNow全記事自動送信。その全てをarchivesで自己実証として記録してきた。
7月以降、GA4のAI流入データ(openai/organic等)を計測して、これらの整備が実際に効果を持ったかを正直に報告する。「やった」で終わらず、「効いたかどうか」まで追うのが当サイトの約束だ。