 WEBサイト
WEBサイト
先週、ある制作会社のディレクターからこんな話を聞いた。「狙ったキーワードでついに1位を取った。なのに、ChatGPTに同じことを質問すると、まったく別のサイトが引用されるんです」。彼は順位を上げる戦いには勝った。けれど、別の戦場で負けていた。
これは特殊な事例ではない。2026年、検索順位とAI引用のあいだに、はっきりとした断層が走り始めている。今日はその断層の正体と、WEBディレクターが明日から何を変えればいいのかを、最新のデータと一緒に配置していく。AI Mode が10億人に届いた日に書いたことの、次の一手だ。
順位は上がった。なのに、AIは別のサイトを引用していた
まず、いま起きている現象を数字で確認しよう。2026年、検索結果のTop10とAI引用元の重なりは、かつての約70%から20%未満まで低下した。「上位10件に入れば、たいていAIも引用してくれる」という時代の常識が、わずか1年ほどで崩れたことになる。
一方で、AI Overview(検索結果上部に出る要約)の引用元を調べると、その約92%はTop10ランキングのページ由来だという別の調査もある。「重なりは20%未満」と「92%がTop10由来」——一見、真っ向から矛盾する2つの数字だ。だが、これは両立する。そしてこの両立の理解こそが、2026年のSEOの分岐点になる。
「二重構造」— AI Overview と AI Mode は別の引用をしている
矛盾の答えは、AIが2つの異なる引用の仕方をしている、という事実にある。

AI Overview(スナップショット型)は、検索クエリに対する一発の要約だ。これは従来の検索ランキングと強く連動していて、上位ページから引用する。だから「92%がTop10由来」になる。ここはまだ、順位の世界の延長線上にある。
ところがAI Mode や ChatGPT・Perplexity のような会話型は違う。ユーザーが何度も問いを重ね、AIが内部でクエリを分解(ファンアウト)して、それぞれに最適な情報源を探しにいく。このとき選ばれるのは「順位が高いページ」ではなく「そのサブ質問に、確かな存在として答えられるエンティティ」だ。だから会話型では、Top10との重なりが20%未満まで落ちる。
順位の世界と、エンティティの世界。WEBディレクターはいま、この2つの地図を同時に持たなければならなくなった。前者の地図はこれまで通り描ける。問題は、後者の地図を多くのサイトがまだ1枚も持っていないことだ。
AIが見ているのは「エンティティ」だった — ナレッジグラフという地図
では、会話型AIが参照する「エンティティの世界」とは何か。その中心にあるのがGoogleのナレッジグラフだ。いまや50億を超えるエンティティ(もの・人・組織・概念)と、5,000億を超えるファクト(事実)を蓄積している巨大な辞書であり、生成AIのGeminiはこれを学習・参照の基盤のひとつにしている。
ここから、ひとつの因果のチェーンが見えてくる。
- サイト・著者・ブランドがエンティティとして確立される(機械可読な自己説明と、外部からの一貫した言及)
- そのエンティティがGoogleのナレッジグラフに収録される
- ナレッジグラフを参照するAIが、「実在する確かな存在」として引用する
ナレッジグラフに載っていないエンティティは、この入口にすら立てない。順位がいくら高くても、AIにとって「それが何者か」が機械的に確定できなければ、会話の答えには選ばれにくいのだ。
象徴的な数字がある。AIの可視性との相関を調べると、ブランドメンション(言及)の相関は0.664、被リンクは0.218だった。長らくSEOの王様だった被リンクよりも、「あちこちで一貫して言及されている」ことのほうが、AI時代には効く。海外の著名SEO専門家 Aleyda Solis は、2026年の最大の転換を「Rankings & CLIcks(順位とクリック)から、Visibility, Mentions & Citations(可視性・言及・引用)へ」と整理している。
エンティティを確立する90日 — 明日から始める4フェーズ
ここからが本題だ。「エンティティを確立しろ」と言われても抽象的すぎる。だから、コストが小さく複利で効く順に、90日のアクションプランとして配置する。エンティティと時間、被リンクとアンカーテキストで扱った話を、実装手順に落としたものだと思ってほしい。
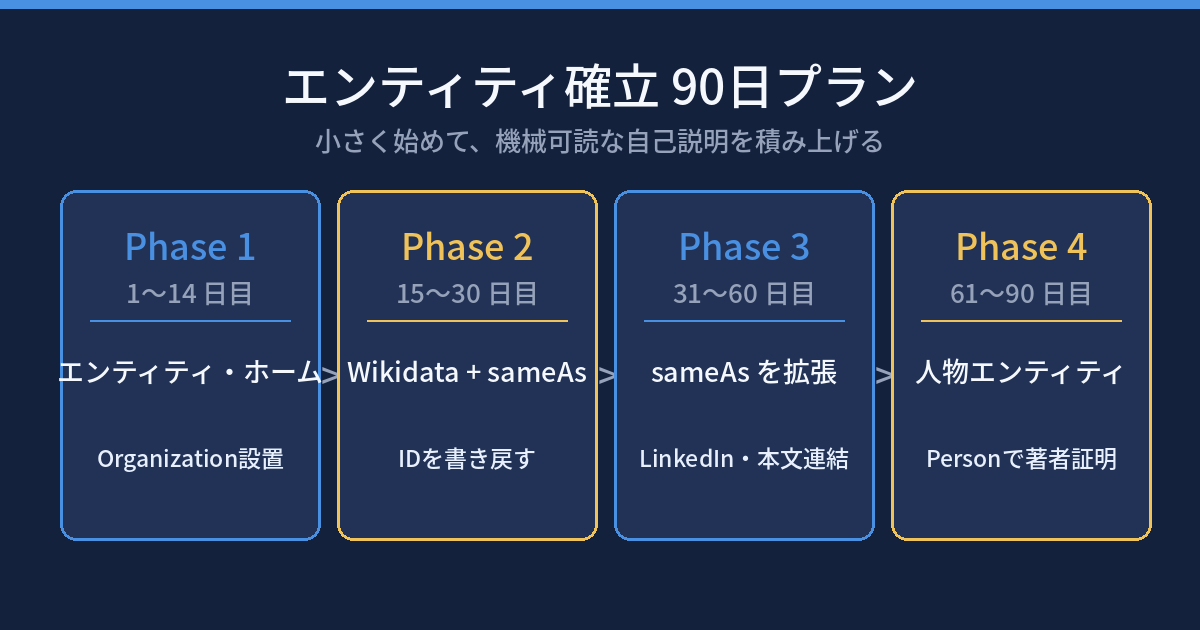
Phase 1(1〜14日目)エンティティ・ホームを作る
会社情報ページに、創業日・経営者名・事業内容・対象地域を正確に書く。そのうえで Organization の構造化データ(JSON-LD)を設置する。@id に正規ドメインのURL、name / url / foundingDate / description / logo。この段階では sameAs は空でいい。まず「自分は何者か」を1か所、機械可読で宣言する。
Phase 2(15〜30日目)Wikidata登録 + sameAs
Wikidata に自社のアイテムを作る。最低限のプロパティは、種別(orGAnization)・創業日・公式サイトURL・説明文だ。Wikidata は被リンクのような特筆性の壁がなく、誰でも登録できるうえ、ナレッジグラフの主要な入力源になっている。割り当てられたIDを、Phase 1で作った Organization の sameAs に書き戻す。これが「最も強力な自己紹介の証明書」になる。
Phase 3(31〜60日目)sameAs を広げ、本文を繋ぐ
sameAs に LinkedIn 企業ページ・各種業界ディレクトリを足す。さらに、記事本文の固有名詞(人・概念・地名)を、機械可読な参照で外部の確定エンティティに紐づけていく。点だった情報が、線で繋がり始める段階だ。
Phase 4(61〜90日目)人物(Person)を立てる
経営陣や著者について、同じことを Person で行う。個人のエンティティを、雇用関係で組織に接続する。E-E-A-Tの「経験・専門性」を、文章だけでなく構造でも証明する。
そして90日以降は、PRと第三者からの言及に注力する。ここで大事な事実を一つ。すべての言及にリンクは要らない。リンクのないブランドメンションでも、エンティティの裏付けに寄与する。「言及されること」そのものが、もう資産なのだ。
スキーマを消すな — 「表示トリガー」から「信頼シグナル」へ
ここで多くのディレクターが2026年に判断を誤りかけている論点に触れたい。2026年5月7日、GoogleはFAQリッチリザルトの表示を完全に終了した。検索結果からあの開閉式のFAQ表示が消え、6月にはレポートやテストツールのサポートも外れていく。これを見て「ではFAQスキーマはもう要らない、消そう」と考えるなら、それは逆だ。
Google自身がこう言っている。「FAQ構造化データはそのまま残してよい。マークアップは問題を起こさないが、可視的な結果も生まない」。つまり「消すな、AIに読ませろ」ということだ。実際、構造化データの役割は静かに転換した。ある分析はこう核心を突いている——「AIはスキーマを"表示トリガー"ではなく"信頼シグナル"として使う」。
構造化データの新しい主目的は、AIが回答を合成する最中のエンティティ解決(これは何者かの確定)とクレーム検証(この主張は本当かの裏取り)だ。事実、適切なスキーマを持つページはAI Mode での引用率が3.2倍高い。FAQリッチリザルトが47%減った一方で、スキーマ自体の価値はむしろ上がっている。この「役立つ/役立たない」の正確な切り分けは構造化データはAIのコンテンツ理解に役立たない!? という実験の読み解きと構造化データとLLMに詳しく書いた。コウゾウ(構造化データ生成ツール)でJSON-LDを作り、AI対応診断ツールで実装状況を点検してほしい。
クロールされても、引用されない — 「クロール対リファラー比」という体温計
もう一つ、2026年に持っておくべき自己点検の指標がある。クロール対リファラー比だ。AIのクローラーが自サイトを何回読みにきて、その結果として何回の訪問者を送り返してくれたか、の比率である。
数字を見ると背筋が伸びる。あるレポートでは、ClaudeBot は 23,951:1、GPTBot は 1,276:1。つまりClaudeBotはサイトをおよそ2万4千回読みにきて、送客は1回ということだ。対照的に、従来型の DuckDuckGo は約1.5:1——読んだぶん、ほぼ等価で送り返してくれる。AIクローラーは、大量に読むが、ほとんど送客しない。
これは構造的な緊張を生んでいる。2026年5月28日、CNNがPerplexityを提訴した。17,000本を超える記事・画像・動画を無断でスクレイピングしたという主張だ。テレビネットワークとして初のAI著作権訴訟になる。CNNは「コンテンツを作る者から盗むことが許されてはならない」と言い、Perplexity は「事実は著作権で保護できない」と返した。引用と窃取の境界線が、いま法廷で引き直されようとしている。
WEBディレクターにとっての実務的な含意はこうだ。クロールされる回数を誇るな。「読まれた数」ではなく「引用され、送客された数」を測れ。そして引用されるための条件は、結局この記事の前半で配置してきた——エンティティの確立と、信頼シグナルとしての構造化データに収束する。これは私が3層計測のOSで書いた「季節性に振れない判断軸を持て」という話とも、まっすぐ繋がっている。
May Core Update 完了直前の今、やること・やってはいけないこと
最後に、足元の話を。2026年5月21日に始まった May 2026 Core Update は、最大2週間、つまり6月初旬(6/2〜6/4頃)に完了する見込みだ。この記事を書いている今、まだロールアウトの最中にある。
専門家の助言は一致している。やってはいけないのは、ロールアウト中の慌てた変更だ。明確な技術的不具合を除いて、順位が下がったからとタイトルをいじったりキーワードを足したりするな。データはまだ不安定で、その変更が効いたのか変動の揺れなのか判別できない。
やるべきは、完了を待って、クリーンなデータでパターンを読むこと。単一キーワードの上下で一喜一憂せず、ページタイプ・検索意図・フォルダ単位で「どういう種類のページが動いたか」を診断する。そして弱いページを、小手先でなく作り替える——独自の洞察、確かな事例、明快な構造、出典、新しいデータ、そして著者の証明を載せて。SEO専門家 Lily Ray は「勝者は first-party・公式ソース。Googleは権威あるソースへ可視性を傾けている」と見ている。権威とは、まさにエンティティの確立そのものだ。
当サイトも、この数字の季節を観察しながら走っている。先日、未強化だった記事を大量に noindex にして、サイトマップを1,271件から288件まで絞った。数で勝負するのをやめ、本物だけを残すと決めたからだ。Core Update のたびに揺れる検索の海で、何を残し、何を手放すか——その判断こそ、ディレクターの仕事だと思っている。
明日のあなたが変えられること
長くなった。最後に、明日の朝いちばんで動かせるチェックリストとして配置し直す。
- 会社情報ページに
Organizationスキーマを置く(創業日・名称・URL・説明・ロゴ)。今日できる ✅ 当サイト実施済 - Wikidata に自社を登録し、IDを
sameAsに書き戻す。今週できる 🔧 sameAsは実装済/Wikidataは着手中 - FAQスキーマを消さない。表示は消えても、AIの信頼シグナルとして残す ✅ 当サイト実施済
- 「クロール数」ではなく「引用・送客数」を測る指標に切り替える ✅ 当サイト実施中
- Core Update が完了する6月初旬まで、慌てた変更をしない。完了後にパターンで診断する ✅ 当サイト実施中
- 被リンクの本数より、一貫したブランドメンションを増やす。リンクなしの言及も資産だ ✅ 当サイト実施中
正直な自己開示 — 当サイトの現在地
偉そうに6つ並べた手前、当サイト自身の現在地も正直に晒しておく。Organization と FAQ のスキーマは実装済み、計測・静観・メンションは日々の運用で実践中だ。そして sameAs ——この記事を書きながら「当サイトもまだ公式アカウントを sameAs に入れていない」ことに気づいて、その場で実装した(トップの OrGAnization に公式 Facebook と X を追加)。残る Wikidata 登録だけは、これから着手する。
「やるべきだ」と書いたことは、自分でもやる。まだやっていなければ、できていないと正直に書いて、すぐ追いつく。当サイトがやっているかどうかで推奨を選り好みはしない——読者にとって本当に必要なことだけを書く。それが当サイトの流儀だ。
順位を上げる戦いは、これからも続く。でも、それと並んで、もう一つの地図——「あなたが何者かを、機械に確かに伝える」という地図を描き始めてほしい。AIに引用されるサイトは、声が大きいサイトではない。自分が何者かを、静かに、正確に、機械可読で語れるサイトだ。
音を出す前の沈黙に、一文を置いておく。それが私のやり方だ。あなたのサイトにも、その一文を。
📌 関連コンテンツ
- 🔧 AI対応診断ツール — 構造化データ・エンティティ信号の実装状況を20項目で診断
- 🔧 コウゾウ — 構造化データ生成ツール — OrGAnization / Person スキーマのJSON-LDを生成
- 📰 エンティティと時間、被リンクとアンカーテキスト
- 📰 構造化データとLLM:役立つ場合と役立たない場合
- 📰 構造化データはAIのコンテンツ理解に役立たない!? — 実験の読み解き
- 📝 AI Mode 10億人突破 — 検索は会話になった。WEBディレクターは何をすべきか
- 📝 季節性に振れない3層計測のOS