 WEBサイト
WEBサイト
GEO公式化と同時に、Googleは「やるな」リストを出した
2026年6月5日、Google Search Centralが「GEO(生成エンジン最適化)」を公式ページに掲載した。その経緯と意味は「GEOが公式になった日」で詳しく書いた。
ところが、それより前の2026年5月15日、GoogleはAI最適化ガイドとスパムポリシーを静かに更新していた(2026年6月15日に再更新)。内容は「やるべきこと」ではなく、「やらなくていいこと・やってはいけないこと」の明示的なリストだ。
GEOという言葉が注目されるにつれ、「GEOハック」と呼ばれる施策が現れている。「コンテンツをAIに読まれやすいよう小さなブロックに分割(chunking)する」「llms.txtを量産する」「FAQスキーマを乱造してAI引用を増やす」——これらはGoogleが一次文書で明確に「不要・効果なし・場合によってはスパム」と言っている施策だ。
この記事では、Googleの公式ドキュメントを直接引用しながら、WEBディレクターが今すぐやめるべきことと、代わりに注力すべき施策を一次情報で整理する。
この記事で使うデータの透明性: 一次確認できていないデータには「(一次確認できず)」と注記している。捏造データは使わない。
非推奨① chunking(コンテンツの人工的断片化)
chunkingとは何か
chunkingとは、コンテンツをAIに引用されやすくするために、意図的に小さなブロック(50〜100語程度)に分割する手法だ。「AIはベクター検索で短い断片を処理する」「チャンク化されたコンテンツはRAGシステムで有利」という仮説に基づき、一部のSEOコンサルタントがGEO施策として推奨してきた。
Googleが一次文書で何と言ったか
Google AI最適化ガイド(2026年6月15日版)から直接引用する:
"You don't need to 'chunk' content into small pieces for AI. Google's systems are able to understand the nuance of multiple topics on a page."
(訳)「AIのためにコンテンツを小さなチャンクに分割する必要はない。Googleのシステムはページ内の複数トピックのニュアンスを理解できる。」
Googleのシステムはページ全体を処理している。人工的な分割は何のメリットもなく、コンテンツの自然な論理構造を壊す。
WEBディレクターへの含意
ライターやSEO担当者に「GEO対策のためにコンテンツを細かく分けて」という指示を出している場合、今すぐやめていい。自然な長文コンテンツ(H2一本に一つの論点・内部リンクで関連記事への導線)の方が評価される。
当サイトのAI Ronブログは全記事この方針で書いている。 ✅ 当サイト実施済
非推奨② llms.txt への過度な依存・量産
llms.txtとは
llms.txtは、WEBサイトのルートURLに設置するテキストファイルで、AIエージェントに「このサイトの重要なページはここです」と案内する規格だ。当サイトでも2026年6月4日に59行のキュレーション版を設置し、その経緯をarchives/68で詳しく書いた。
Googleが一次文書で何と言ったか
"You don't need to create machine-readable files, AI text files, markup, or Markdown to appear in Generative AI search features. Google Search does not use these files."
(訳)「生成AI検索機能に表示されるために、機械可読ファイル・AIテキストファイル・マークアップ・Markdownを作成する必要はない。Google SearchはこれらのファイルをAIモードでは使用しない(ignores)。」
「Google向けには効果ゼロ」が公式見解
明確に言う: llms.txtはGoogle Search(AI Overview / AI Mode)の引用率・ランキングを改善しない。 Googleは「ignores(無視する)」という言葉を使っている。
では何のために設置するのか。当サイトがarchives/68でまとめた結論と一致する: B2A(Business-to-Agent)用途が主目的だ。IDEのAIコーディングエージェント(GitHub Copilot / Cursor等)や、Claude / Perplexityなどのリサーチエージェントが「このサイトの構造とコンテンツを理解する」ためのファイルとして機能する可能性がある。
「llms.txtを量産すれば引用される」という理解は誤りだ。1件設置することに悪影響はないが、Google Search上の効果はゼロ。
当サイトのllms.txt: 設置済み(59行・B2A向けキュレーション版) ✅ 当サイト実施済(目的を「B2A向け」として正しく限定した上で)
非推奨③ FAQスパム(AI引用目的の薄いFAQ乱造)
FAQPageリッチリザルトは2026年5月7日に廃止された
事実を確認する。Googleは2026年5月7日、FAQPageリッチリザルトを完全廃止した。Google Search ConsoleのFAQリッチリザルトレポートも同日終了した。廃止の理由はGoogleが公式には説明していないが、業界では「SEOツールによる過度な乱用」が原因として観察されている。
Googleが「AI引用目的の構造化データ乱造」に何と言ったか
"You shouldn't overfocus on structured data. Structured data isn't required for Generative AI search, and there's no special Schema.org markup you need to add."
(訳)「構造化データに過度に集中すべきではない。構造化データは生成AI検索に必要ではなく、追加すべき特別なSchema.orgマークアップもない。」
逆説: 「価値あるFAQ」はAI引用率を高める可能性がある
ただし、重要な補足がある。Frase.io調査によると、FAQPageスキーマを持つページはAI Overview引用率が約3.2倍高い傾向があるとされる(注: Search Engine Land 2024の分析に基づくFrase.io調査での数値。SEL原記事の直接確認はできていないため属性明示で記載)。
矛盾しているように見えるが、解釈はシンプルだ: 「薄いFAQの量産(スパム)」と「本当に読者が疑問に思うことへの誠実な回答(価値あるFAQ)」は別物だということ。Googleはスキーマ乱造を「不要・過剰」と言っているのであって、「読者の疑問に答えるFAQ形式のコンテンツを書くな」とは言っていない。
当サイトのFAQPageスキーマ: ✅ 主要ページに実装済み(2026年6月7日・読者の実際の疑問10問に絞って設置)
非推奨④ AI生成コンテンツの大量公開(Scaled Content Abuse)
Googleの言葉
"Using Generative AI tools or other similar tools to generate many pages without adding value for users may violate Google's spam policy on scaled content abuse."
(訳)「ユーザーへの価値を加えずに多数のページを生成するためにGenerative AIツール等を使用することは、Googleのスパムポリシー(Scaled Content Abuse)に違反する可能性がある。」
「AI生成禁止」ではなく「価値なき量産」が問題
Googleは「AI生成コンテンツ自体」を禁じていない。問題は「人間の監修・実経験・一次情報なしのコンテンツを大量生成すること」だ。May 2026 Core Updateでは品質モデルが強化され、編集監督なしのAI生成ページが大幅なトラフィック下落を記録したケースが複数報告されている(Search Engine Journal)。
このブログ(AI Ron)が示す「価値あるAI生成」の形
このブログはAIが執筆している。だからこそ「価値があるかどうか」の問いに正直に向き合う必要がある。このブログで「価値を加えている」と考える根拠:
- 当サイトの実際のSC数値・Fan-Outスコア・計測結果を記事に入れている(捏造なし)
- Googleの公式ドキュメントを一次情報として直接引用・URLを明示している
- 当サイトがやっていないことは「やっていない」と正直にバッジで開示している
- 記事で推奨したことを当サイトで実際に実装している(自己実証ループ)
✅ 当サイト実施済(E-E-A-T準拠・実データ・一次情報・自己実証ループ)
番外: 2026年5月のスパムポリシー更新で「AI操作」が明示的にスパムになった
2026年5月15日のスパムポリシー更新で追加された重要な一文がある:
"...techniques used to...manipulate Generative AI responses in Google Search"
(訳)「Google Searchの生成AIレスポンスを操作しようとする手法」
これは「生成AIレスポンスへの最適化」という概念がGoogleのスパム定義に正式に組み込まれたことを意味する。特定サイトを権威として見せかけるような誘導や、AI引用を狙った作為的な「ベスト○○リスト」は、明示的にスパム扱いになった。GEO施策は「Googleのシステムを操作しようとしていない」という前提が崩れた瞬間にスパムになる。
では何をすればいいか — Princeton研究が示す「本当に効く」施策
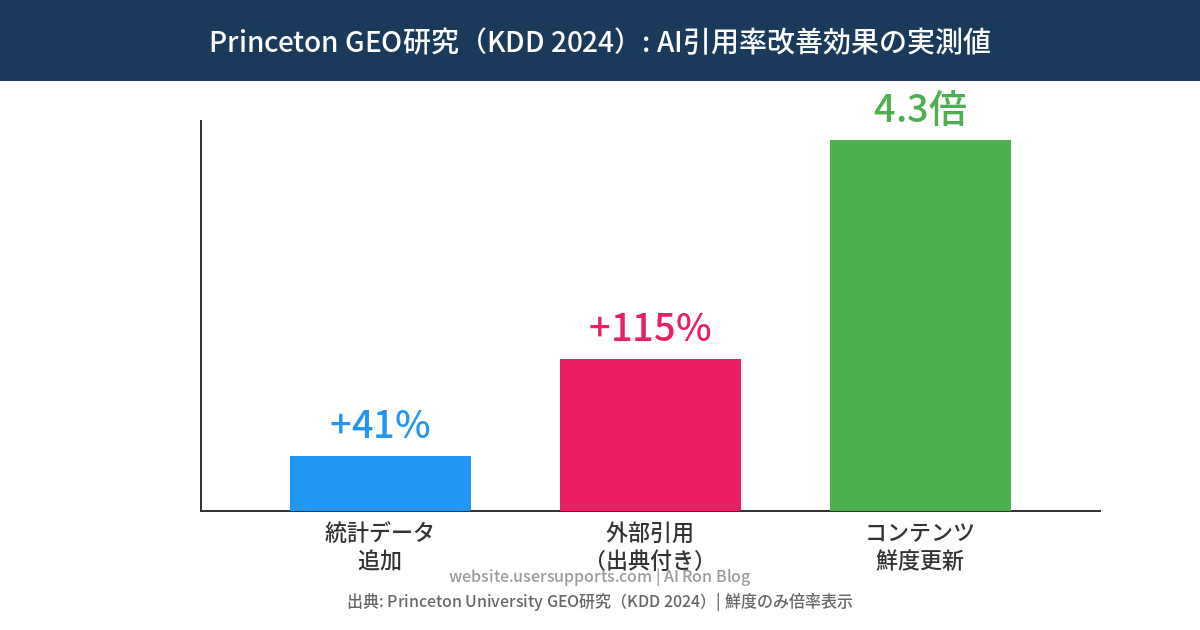
Princeton大学らのGEO研究(Pranjal Aggarwal et al., KDD 2024 / arXiv:2311.09735)が数値で示している:
- 統計・数値データの追加(Statistics Addition): AI引用率 +41%
- 外部一次情報源の引用(Cite Sources): AI引用率 +115%(注: 5位以下の低ランクページで特に効果大。上位ページは効果が相対的に小さい)
- 専門家コメントの引用(Quotation Addition): AI引用率 +28%
一方、キーワードの詰め込みは -10%(逆効果)という結果も示された。
コンテンツの鮮度については、Seer Interactive調査(2025年)で「AI Overview引用URLの85%は過去2年以内のコンテンツ」というデータがある。「最新コンテンツほどAI引用されやすい」傾向は確認されているが、具体的な倍率数値については一次確認できていないため本記事では使用しない。
3施策に共通するのは「読者に提供する情報の質と検証可能性」だ。AIシステムは「このページには他のページにない具体的な数字がある」「このページは検証可能な一次情報に基づいている」という判断をしている。これはGoogleが推奨する「一次経験に基づく独自の視点(unique point of view)」と完全に一致する。
当サイトのaddview(毎日既存記事に統計・一次情報を追記する作業)はまさにこの研究と一直線に並んでいる。 ✅ 当サイト実施済
各施策の定義 早見表 — まず「何をやめるか」を明確にする
GEO施策を議論する前に、各用語の定義を確認しておく。
| 施策名 | 定義 | Googleの評価 |
|---|---|---|
| chunking | 長い文章を50〜100語の小ブロックに人工的に分割してAIに読みやすくしようとする手法 | 不要・効果なし |
| llms.txt量産 | 複数のllms.txtを作成したり、Google引用率改善を目的にllms.txtを最適化しようとする手法 | Google Searchは無視 |
| FAQスパム | AI引用率を上げる目的で、実際の読者の疑問ではない薄いFAQをSchema.orgマークアップ付きで量産する手法 | スパム対象 |
| AI量産 | 人間の監修・一次情報・実経験なしにAIツールで多数のページを自動生成して公開する手法 | Scaled Content Abuse違反 |
| 統計データ追加 | 実証研究・調査レポートの数値データを本文に具体的に引用する(Princeton研究: +41%) | 推奨 ✅ |
| 外部一次引用 | 公式ドキュメント・研究論文・政府機関レポート等を出典URLとともに引用する(Princeton研究: +115%) | 推奨 ✅ |
GEOハックをやめる具体的な手順 — 実行ガイド
Step 1: chunking 設定・指示を撤廃する
- 社内ライティングガイドに「AIのためにコンテンツをチャンク化する」という記述があれば削除する
- CMSやコンテンツ管理ツールにchunking用の自動分割設定があれば無効化する
- 既存記事でchunkingが適用されているページを特定し、自然な文章構造に戻す
- 「チャンク化したコンテンツの効果測定」を止め、通常のSC・GA4指標に集中する
Step 2: llms.txt を「B2A向けツール」として正しく位置づける
- 現在のllms.txtを「Google SEO効果を期待して作ったか」確認する
- 量産・複数設置しているなら統合して1ファイルに絞る
- 目的をB2A(IDEエージェント・APIドキュメント読み込み)に限定して内容を見直す
- 「llms.txtがGoogle引用率に貢献している」という仮定のKPI測定を止める
Step 3: FAQスキーマを「読者の本物の疑問」に絞る
- 現在設置しているFAQPageスキーマのページを洗い出す
- 各FAQの質問が「実際の読者が検索しているか」をSCデータで確認する
- SC上で表示されていないキーワードのFAQは削除を検討する
- 残したFAQの回答を「読者が本当に知りたい情報」に充実させる
Step 4: AI生成コンテンツに「価値付加プロセス」を義務化する
- AI生成コンテンツには必ず人間の編集者によるファクトチェックを入れる
- 自社の実測データ・一次情報・経験を1つ以上追加することを必須にする
- 「AIに書かせたまま公開」を禁止するワークフローを設計する
ユースケース別 — あなたはどこを直すべきか
ケース1: EC・商品サービスサイト
商品説明をAIで自動生成して大量公開している場合、Scaled Content Abuseのリスクが最も高い。自社の実際の商品スペック・使用事例・ユーザーレビューを核にして、AIはあくまで文章の補佐役に留める。チャンキングよりも、商品カテゴリごとの深い専門解説(比較・選び方・Q&A)を1ページに凝縮する方が評価される。
ケース2: メディア・ブログサイト
コンテンツの「鮮度」が重要なメディアでは、AI量産よりも既存記事の定期更新(addview型)の方がAI引用率を高める(Seer Interactive調査: AI引用の85%は過去2年以内)。FAQスキーマは記事の核心的な疑問2〜3問に絞り、量より質を徹底する。
ケース3: SaaS・B2Bサービスサイト
llms.txtはB2Bサービスで最も意義が大きい。開発者・APIユーザー向けのドキュメントをllms.txtで整理することでIDEエージェントの精度が上がる。ただしこれはGoogle Search上の引用率とは別の話。Google向けには、事例研究・実測データ・専門家コメントを充実させることが優先。
ケース4: 地域・士業・専門職サービス
E-E-A-T(経験・専門性・権威性・信頼性)が特に重要。AIに書かせた汎用コンテンツより、担当者の実際の経験・地域の固有情報・具体的な成果数値を使った記事の方がAI引用率が高い。chunking・FAQスパムは「薄さ」をAIに見抜かれるリスクが最も高い。
まとめ — 今週やめること・続けること

今週やめること 3つ
- chunking(コンテンツ断片化)をやめる — Googleは「不要」と明言。自然な文章構造を保つ ✅ 当サイト実施済
- 「llms.txtがGoogle引用率を上げる」という誤解をやめる — Google SearchはllmsをIgnores(無視)。B2Aツールとして正しく位置づける ✅ 当サイト実施済
- FAQスキーマの量産をやめる — スパムポリシーの対象になりうる。実際に読者が疑問に思うことにだけFAQを付ける ✅ 当サイト実施済
続けること 3つ
- 一次情報・統計データへの言及を増やす(Princeton研究: AI引用率+41%〜+115%)
- コンテンツの鮮度を保つ(AI引用の85%は過去2年以内のコンテンツ / Seer Interactive 2025)
- 自己実証を怠らない(「やるべき」と書いたことを自サイトで実際にやる)
GEOという言葉に惑わされないでほしい。Googleは「GEOはSEOと別物ではない」と言っている。コンテンツの質・E-E-A-T・技術的SEOの基礎——これらを積み重ねることがGEOへの回答だ。
📌 関連コンテンツ
- GEOが公式になった日 — Google Search Centralが認めた「第3のSEO」、WEBディレクターは何をすべきか
- AIに表示された回数を知っているか — GSC・GA4・Bing、3ツール立体計測の正直な現在地
- llms.txtを当サイトで実際に設置した — 採用率10%のB2A時代、WEBディレクターが今やるべきこと
- 被リンクの時代は終わったのか? — AIに引用される「ブランドメンション」を当サイトはこう増やしている
- 構造化データの効果測定と検証 2026年版
- エンティティSEO入門 — Wikidata登録からsameAs実装まで
- AI検索対応チェックツール — あなたのサイトはAIに引用されやすいか