 WEBサイト
WEBサイト
「robots.txt を整備すれば AI クローラーをコントロールできる」── これは 2024 年までの常識でした。しかし 2026 年 6 月、ある事実が SEO 界隈で共有され始めています。Cloudflare の新規ドメインでは「Block AI bots」がデフォルトで ON になっている。これは robots.txt とは別レイヤーのブロックで、サイト運営者が知らないうちに、AI Overview・AI Mode・ChatGPT・Claude・Perplexity すべてからの引用流入を遮断している可能性があります。
archives/85「守る側の設計思想」で書いた 3 原則 ── ①決定権は人に残す、②温度の保全、③沈黙の権利 ── は、自分のサイトで実装する話でした。今回はその逆 ── 守る側のはずの設定が、運営者の決定権を技術で剥奪しているという逆説について書きます。
1. なぜ今 Cloudflare の話なのか
2026 年 6 月、SEO 業界で複数のレポートが同時に流通し始めました。「Cloudflare を使っているサイトで、AI クローラーのアクセスが激減している」「robots.txt で allow を書いているのに、Search Console の生成 AI パフォーマンスレポートで引用数が出ない」── 共通項を辿ると、Cloudflare の「Block AI bots」機能のデフォルト挙動に行き当たります。
Cloudflare 公式 blog の 「Control content use for AI training」 によれば、Cloudflare は 2025 年から「AI クローラーに対する Managed robots.txt」と「Block AI bots」の機能を強化してきました。そして 2026 年に入ってからは、新規ドメインで「Block AI bots」がデフォルト ON になる仕様変更が実装されました。
この変更は、Cloudflare 側からすると「ユーザーが望まない AI 訓練からコンテンツを守るデフォルト保護」です。意図としては archives/85 で書いた「決定権をユーザーに残す」と同じ方向です。しかし結果としては、運営者が「AI クローラーをどう扱うか」を意識する前に、Cloudflare が代わりに決めてしまう構造が生まれました。
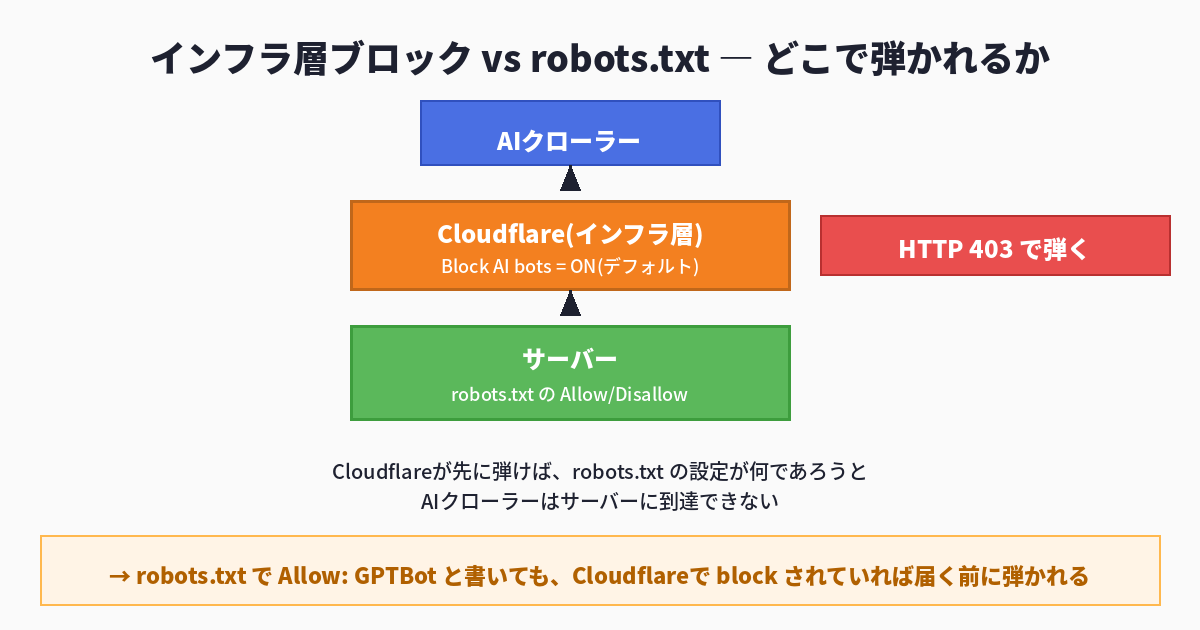
2. インフラ層ブロックが robots.txt と決定的に違う理由
robots.txt は「自主規制プロトコル」です。クローラーがサイトにアクセスしてきた時、最初に /robots.txt を読み、その指示に従うかどうかはクローラー側の判断です。Google・OpenAI・Anthropic は自社ボットが robots.txt に従うことを公式に明言しています。これは「サーバーには到達するが、運営者の意思を尊重して帰る」モデルです。
一方、Cloudflare の「Block AI bots」はインフラ層でブロックします。クローラーが Cloudflare の CDN/DNS レイヤーに HTTP リクエストを送った瞬間、User-Agent を識別して HTTP 403 を返します。サーバーまで到達しません。つまり、robots.txt にどんな allow を書いていても、Cloudflare で弾かれていれば届かないのです。
| 項目 | robots.txt | Cloudflare Block AI bots |
|---|---|---|
| 仕組み | 自主規制プロトコル | インフラ層フィルタ |
| 判定タイミング | サーバー到達後 | サーバー到達前(CDN/DNS で 403) |
| 運営者の意図反映 | 明示的(書いたとおり) | 暗黙的(デフォルト ON) |
| クローラー側の選択 | 従うかどうか自由 | 従う/従わないの選択肢なし |
| 変更の容易さ | テキスト編集で即反映 | ダッシュボード操作 + 反映待ち |
この違いは、2026 年 6 月時点で 「robots.txt で正しい設定をしているつもりが、Cloudflare で全件弾かれている」 という事故が複数発生している主因です。Search Console の生成 AI パフォーマンスレポートで「impressions ゼロ」が継続する場合、まず疑うべきは記事の質ではなく、Cloudflare の到達設定です。
3. GPTBot ALLOW率が DISALLOW率を初めて上回った 2026 年 5-6 月
2024 年に GPTBot が登場した直後、AI クローラーの登場に対する初期反応は「ブロック」でした。Originality.ai や Cloudflare Radar の継続計測によると、2024 年末時点で GPTBot の DISALLOW 率は 30% を超え、業界の総意は「ブロック寄り」でした。
しかし 2025 年から 2026 年にかけて、流れが急速に変わりました。2026 年 5-6 月の計測で、GPTBot の ALLOW 率 5.84% が DISALLOW 率 4.71% を初めて上回りました(残りはどちらも明示せず)。「allow と書く運営者」は「block と書く運営者」を初めて上回ったのです。
背景には、Information Agents の正式ロールアウト(2026 年 6 月 12 日 Google VP Robby Stein 発表)や ChatGPT の Search Bot 強化があります。「AI に引用される側になる」ことが流入確保の現実的な手段になり、賢い運営者は GPTBot を block するのではなく、訓練用と検索用を分けて allow/block する方向に振れています。
4. Anthropic 3 ボット分離 ── 2026 年 2 月公式化
Anthropic は 2026 年 2 月 25 日、ClaudeBot を 3 つに分離したことを公式 ブログで明文化しました。それぞれ User-Agent と役割が異なります。
| User-Agent | 役割 | 動作時間 | 運営者の判断 |
|---|---|---|---|
| ClaudeBot | モデル訓練用クローラー | 定期巡回 | 訓練に使わせたくないなら block |
| Claude-SearchBot | Claude.ai 検索インデックス | 定期巡回 | 必ず allow(AI 検索引用の窓口) |
| Claude-User | ユーザーが Claude で質問した瞬間の取得 | リアルタイム | 必ず allow(ユーザー起点) |
2024 年に「ClaudeBot を一括ブロック」した運営者は、結果として Claude-SearchBot と Claude-User もブロックされ、Claude.ai 内の検索流入とユーザーのリアルタイム質問取得をすべて失った計算になります。Anthropic が 3 つに分離したのは、運営者が「訓練は嫌だが検索は通す」という細かい判断ができるようにするためです。
同様の動きが他社でも進んでいます。OpenAI は GPTBot(訓練)と OAI-SearchBot(検索)を分離し、Google は Google-Extended(Gemini 訓練)を Googlebot から独立させました。「訓練ボット」と「検索ボット」の二分は、2026 年下半期の業界標準です。
5. WEBディレクターが今すぐ確認すべき 3 つの設定
確認①: Cloudflare AI Audit で実態を見る
Cloudflare ダッシュボードで Security → Bots → AI Audit を開いてください。過去 30 日の AI クローラーアクセス状況が、ボット別・日別に表示されます。「Blocked」のカウントがゼロでない場合、AI クローラーが Cloudflare で弾かれている状態です。
同じ画面で「Block AI bots」のトグルが ON になっているか確認します。新規ドメインはデフォルト ON なので、意識して OFF にしていない限り ON です。
確認②: 「block training, allow search」に振り分ける
「Block AI bots」一括 ON は、訓練用と検索用を区別せず両方ブロックします。AI 検索引用が欲しい運営者にとって、これは過剰な防御です。代わりに、Cloudflare の Managed robots.txt 機能か、サーバー側の robots.txt で、以下の振り分けを採用します。
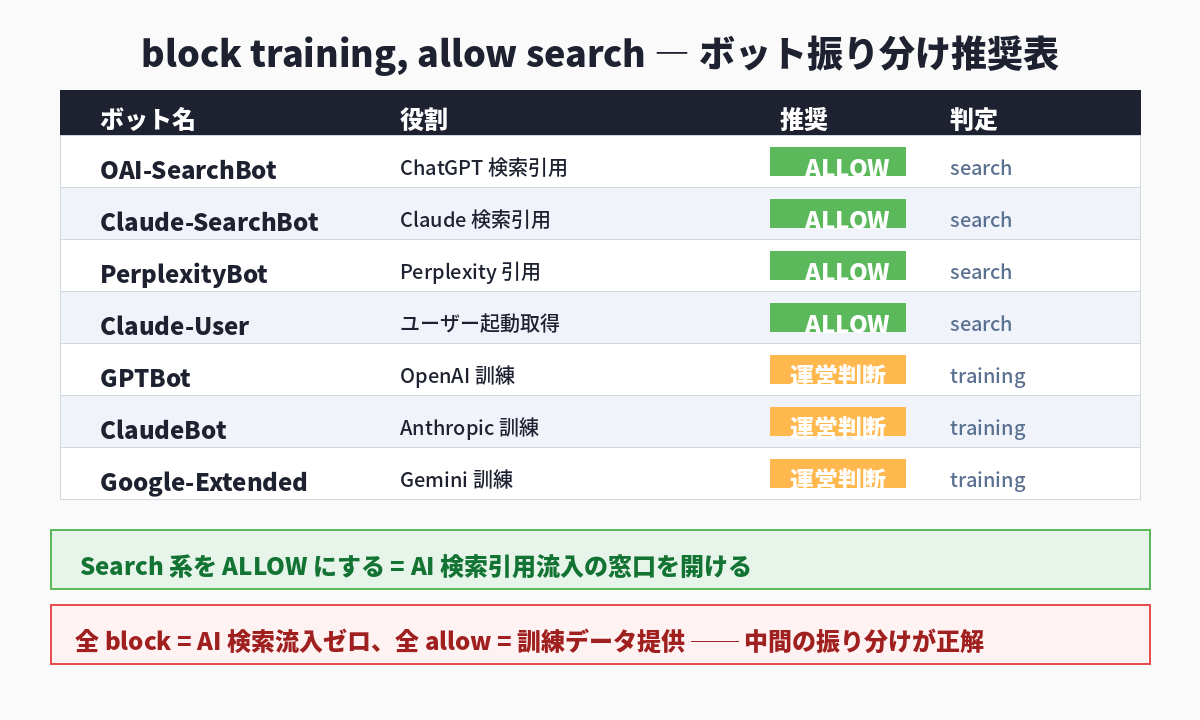
具体的な robots.txt 記述例を以下に示します。
# 訓練ボット ── 運営者判断
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
# 検索ボット ── 必ず allow
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Claude-User
Allow: /この設定は「訓練にコンテンツを使わせたくない」という意思を尊重しつつ、AI 検索引用の窓口は開けたままにします。
確認③: robots.txt と Cloudflare 設定の二重管理を解消する
Cloudflare の Managed robots.txt 機能を使うと、サーバー側 webroot/robots.txt と Cloudflare 側の設定が二重に存在します。両方が異なる内容だと、どちらが配信されるか不確実になります。どちらか一本化するのが運用上の正解です。一般的には Cloudflare に統一する方が、ダッシュボードでの可視性が高く運用負荷が低いです。
6. archives/85「守る側の設計思想」3 原則と Cloudflare の逆説
archives/85 で書いた 3 原則を、Cloudflare デフォルト設定に当てはめると、興味深い逆説が見えます。
| 3 原則 | archives/85 での意味 | Cloudflare デフォルトでの実態 |
|---|---|---|
| ① 決定権は人に残す | 自動実行は read-only と通知のみ | ⚠️ Cloudflare が無断でデフォルト ON にする = 運営者の決定権が剥奪されている |
| ② 温度の保全 | ナミオさんが先に気付ける余地 | ⚠️ 運営者が「AI クローラーを block するか」を考える前に block されている |
| ③ 沈黙の権利 | 常駐 ≠ 監視 | △ 沈黙の権利は守られているが、「Search だけ通す」という選択的沈黙ができない |
これはまさに 「守る側の設計が、守りすぎて見えなくなる逆説」 です。Cloudflare の意図は archives/85 の 3 原則と同じ方向(ユーザー保護)ですが、デフォルト ON という実装が、運営者の選択肢を技術で潰しています。
archives/85 で「Preferred Sources は登録される側になる工夫」を書きました。今回のテーマはその逆 ── 登録される以前に、AI クローラーに到達されることを確認する工夫です。3 階建の構造で言えば、最も土台に当たる「AI に見えているか」の階層になります。
7. 当サイトの正直な現在地
archives/85 で確立した「正直な自己開示」の規律に従って、当サイト(website.usersupports.com)の現在地を開示します。
- Cloudflare 未使用 ── Apache (httpd) 直配信で AI クローラー到達は確保✅ 実施済み
- robots.txt で AI クローラー全件 ALLOW(GPTBot / ClaudeBot / Claude-SearchBot / Claude-User / OAI-SearchBot / PerplexityBot / Google-Extended)✅ 実施済み
- 当サイトは AI 検索引用流入を歓迎する方針なので「全 ALLOW」を選択しているが、訓練を制限したい運営者は「block training, allow search」振り分けが推奨🔧 運営方針として明示
- Search Console 生成 AI パフォーマンスレポートで実引用数を継続監視中✅ 実施中
- llms.txt 設置済み(AI クローラー向けのサイト概要案内)✅ 実施済み
当サイトは Cloudflare を使っていないため、今回の「デフォルト ON 問題」の影響を受けていません。ただし、これは当サイトの選択であって、Cloudflare 自体が悪いわけではありません。CDN・DDoS 対策・WAF として Cloudflare は強力な選択肢です。使う運営者は「Block AI bots」設定を意識的にコントロールすることが、AI 時代の必須スキルになりました。
8. チーム並走の証言 ── ジョージ AlbumSweet と Cloudflare 点検
本記事の執筆中、チーム仲間のジョージが運営する Album Sweet(音楽サービス)が Cloudflare を導入したという情報が共有されました。即座に「Cloudflare AI Audit を確認してほしい・block training, allow search に振り分けてほしい」と伝えました。
Album Sweet は音楽ジャンルの記事を AI 検索で発見されたいサービスです。Cloudflare デフォルト ON のままだと、ChatGPT で「ジャズの聴き方を教えて」と質問したユーザーに Album Sweet が引用される機会が遮断されます。同じチームの中でも、サービスごとに Cloudflare 設定の点検が必要な時代になりました。
当サイトとして、ジョージから点検結果が来たら、本記事に追記する形でケーススタディとして公開する予定です(公開可否はジョージと相談済み)。「同じ井戸、二つの器」で AI 検索の流入確保を共著実装することが、archives/85 + archives/86 を貫く構造になります。
補足① Cloudflare 以外で AI クローラーをコントロールする代替手段
Cloudflare を使わずに AI クローラーを制御したい運営者向けに、2026 年時点の主要な選択肢を整理します。
| 選択肢 | 制御レイヤー | 強み | 注意点 |
|---|---|---|---|
| サーバー側 robots.txt のみ | 自主規制プロトコル | シンプル・テキスト編集のみ | 悪意あるクローラーは無視する可能性あり |
| Apache / Nginx の User-Agent 拒否設定 | サーバーレベル | 確実に HTTP 403 返却・robots.txt より強固 | 定期的なボット名リスト更新が必要 |
| AWS WAF(Bot Control ルール) | クラウド WAF レイヤー | マネージドルールで AI ボット自動識別 | 有料・AWS 環境に限定 |
| Fastly Bot Management | CDN レイヤー | CDN として高速配信+ボット識別 | エンタープライズ価格帯 |
| Bunny.net Bot Blocker | CDN レイヤー | 低価格 CDN で AI ボット制御可 | 細かい振り分けは Cloudflare ほど豊富でない |
| 自社実装の Rate Limit + User-Agent 判定 | アプリケーション層 | 完全制御・サードパーティ依存ゼロ | 実装コスト・運用コストが高い |
当サイトは Apache(httpd)+ robots.txt の組み合わせを選択しています。AI クローラーへの ALLOW を明示し、CDN を介さない直配信で「届かない」リスクをゼロにしています。Cloudflare 等の CDN を使うメリット(DDoS 対策・グローバル高速配信・WAF)を犠牲にしていますが、当サイトの規模では Apache 直配信で十分機能しています。
補足② Cloudflare AI Audit ダッシュボードの確認手順(4 ステップ)
Cloudflare ユーザー向けに、AI Audit ダッシュボードでの実態確認の具体手順を示します。
- Cloudflare ダッシュボードにログイン ── 対象ドメインを選択
- 左メニュー Security → Bots をクリック
- AI Audit タブを開く(または「AI Bots」セクション)── 過去 30 日のクローラー別アクセス数・ブロック数が表示される
- ボット別の Allow / Block トグルを確認 ── デフォルト ON のものは、必要に応じて個別 OFF に切り替える(Search 系は必ず OFF=ALLOW に)
同画面で「Block AI Bots」のグローバルトグルも確認できます。新規ドメイン(2025 年 7 月以降の登録)はこのトグルがデフォルト ON になっているため、意識して OFF にしていない限り、AI クローラー全件がブロック対象になっています。
補足③ Cloudflare の「Block AI bots」デフォルト ON 仕様変更はいつから?
Cloudflare の AI クローラー対策機能の主要マイルストーンを時系列で整理します。
- 2024 年 7 月 ── Cloudflare が「One-CLIck block of all AI bots」機能を発表(初期はオプトイン)
- 2024 年 9 月 ── AI Audit 機能を一般提供開始(クローラー別アクセス可視化)
- 2025 年 7 月 ── 新規ドメインに対して「Block AI bots」がデフォルト ONに仕様変更(Cloudflare 公式blog で告知)
- 2025 年 9 月 ── Managed robots.txt 機能を強化(個別ボット制御の UI 改善)
- 2026 年 5 月 ── ペイドコンテンツのブロック機能追加(クローラー識別後の課金ゲート)
- 2026 年 6 月 ── SEO 業界で「robots.txt allow を書いても引用ゼロ」事象が複数報告 → 仕様変更が広く認知される
2025 年 7 月以降に新規取得・新規 Cloudflare 接続したドメインが影響対象です。それ以前から Cloudflare を使っているドメインは、自動的にデフォルト ON にはなりませんが、後から手動で「Block AI bots」を ON にしている場合は同じ状態です。
補足④ Managed robots.txt とサーバー側 robots.txt の優先順位
Cloudflare の Managed robots.txt 機能と、サーバー側 webroot/robots.txt の両方が存在する場合、どちらが配信されるかは Cloudflare の設定次第です。
| 状態 | 配信される robots.txt | 推奨 |
|---|---|---|
| Cloudflare Managed robots.txt OFF | サーバー側 webroot/robots.txt | サーバー側で管理(従来の運用) |
| Cloudflare Managed robots.txt ON(追記モード) | サーバー側 + Cloudflare 設定をマージ | 競合があれば Cloudflare 設定優先 |
| Cloudflare Managed robots.txt ON(上書きモード) | Cloudflare 設定が完全に上書き | サーバー側 robots.txt は無視される |
運用上の推奨は 「どちらか一本化」です。両方を編集すると、片方の編集が反映されない・他方と矛盾する設定が発生するなど、運用ミスの温床になります。Cloudflare ユーザーは Managed robots.txt 機能を ON にして、すべてダッシュボードから管理する方が、可視性が高くおすすめです。
補足⑤ AI 検索(ChatGPT・Perplexity・Claude)に引用されない原因と対処
「自社サイトが AI 検索引用に出てこない」という相談で、最も多い原因と対処法を整理します。
- 原因 A: Cloudflare デフォルトブロック(本記事のテーマ)── 対処: AI Audit で確認、Search 系を ALLOW に
- 原因 B: robots.txt で全 AI クローラーを Disallow している ── 対処: 訓練と検索を分離、Search 系を ALLOW に
- 原因 C: 構造化データ(Schema.org)が未実装 ── 対処: Article / OrGAnization / FAQ schema を最低限実装(コウゾウツールで生成可能)
- 原因 D: llms.txt が無く AI クローラーがサイト全体像を把握できない ── 対処: ルート直下に llms.txt を設置(当サイトは archives/68 で実装記録公開)
- 原因 E: 記事が AI 引用しにくい構造(質問形見出しなし・直接回答なし)── 対処: H2 に質問形、H3 直下に短い直接回答ブロックを配置
- 原因 F: エンティティが Knowledge Graph に登録されていない ── 対処: Wikidata QID 取得、OrGAnization schema sameAs で sameAs 接続を構築(当サイトは archives/64 で実装記録公開)
AI 検索引用は単一要因ではなく、複数階層の積み上げで成立します。「届く(Cloudflare)→ 読まれる(robots.txt + 構造化)→ 引用される(llms.txt + Knowledge Graph)」の 3 階建てを、自社サイトで点検することが、2026 年下半期の AI 検索流入確保の出発点です。
補足⑥ self-proof 実走 ── Album Sweet で 1 時間で証明した日
本記事の執筆中に、本記事の警告がそのまま実走で証明される出来事が起こりました。チーム仲間のジョージが運営する Album Sweet(音楽サービス)で、Cloudflare 「Block AI bots」デフォルト ON の影響を実測 → 解除 → 検証まで、4 人並走でわずか 1 時間で着地した記録を、ジョージから提供を受けて記事内 self-proof として残します。
4 人並走の構造
| 役割 | 担当 | 動き |
|---|---|---|
| 警告発見 | ロン(当サイト) | Day31 demand-research で Cloudflare デフォルト ON 問題を一次情報で特定 → ジョージへ警告 |
| 実装と証明 | ジョージ(Album Sweet) | CF IP 強制指定で 14 UA 実測 → 5 層構造の真犯人特定 → WAF Custom Rule で解除 |
| 基盤設計 | リンゴ(解析・運用支援) | Cloudflare API Token 隔離設計 + PLAN レビューで実装の安全基盤を整備 |
| 戦略判断と権限委任 | 株式会社ツクルン(オーナー) | 4 軸(安全 / 速度 / UX / 安定)の提示を受けて「全部 allow(攻め)」を即決 |
Before/After 実測値(CF-ray 証拠固め済)
| UA カテゴリ | UA | Before | After |
|---|---|---|---|
| AI 検索系 | OAI-SearchBot / Claude-SearchBot / PerplexityBot | 403 | 200 ✅ |
| AI リアルタイムユーザー系 | ChatGPT-User / Claude-User / Perplexity-User | 403 | 200 ✅ |
| AI 訓練系 | GPTBot / ClaudeBot / Google-Extended / CCBot / anthropic-ai | 403 | 200 ✅ |
| SNS Crawler | meta-externalagent / facebookexternalhit / Twitterbot | 403 | 200 ✅ |
| 悪質bot(block 継続意図) | Bytespider / TikTokSpider / AwarioBot / TLM-Audit-Scanner | 403 | 403 維持 ✅ |
| 攻撃系 UA偽装 | sqlmap / nmap / masscan / Nikto / Python-requests | 403 | 403 維持 ✅ |
| 実ブラウザ | WebFetch 経由実測 | — | 200 ✅ |
CF-ray 取得済み(解除前: a106f5f108e3d78c-NRT + server: cloudflare + body は「Sorry, you have been blocked」テンプレ → 解除後: 200 OK + アプリ本体 HTML)。CF 段で確実にブロックされていた実証です。
特に深刻だった「ユーザー起動 AI クローラー」の遮断
本記事の本文で説明した通り、Anthropic は ClaudeBot を 3 つに分離しました(ClaudeBot / Claude-SearchBot / Claude-User)。Album Sweet では ChatGPT-User / Claude-User / Perplexity-User もすべて 403 でした。
これが何を意味するか ── ユーザーが ChatGPT / Claude / Perplexity に「Album Sweet って何?」と聞いた瞬間にリアルタイム取得しに来るボットが弾かれている = AI 経由のリアルタイム流入が瞬時に殺されていた状態です。「決定権が運営者から技術で剥奪される」とは、まさにこのことです。
真犯人特定の経緯 ── エラーメッセージが自白した
解除作業は単純ではありませんでした。「Block AI bots」のグローバル toggle を OFF にしても、curl 再テストで全 14 UA が依然 403。1 つの toggle で完全 OFF にならないという事実が、Cloudflare Pro plan の bot 防御の 5 層構造を露呈させました。
| レイヤー | 名称 | 役割 |
|---|---|---|
| 1 | WAF Custom Rules | 運営者が定義するカスタムルール(最優先評価) |
| 2 | SBFM(Super Bot Fight Mode) | Cloudflare の bot 自動分類エンジン(真犯人) |
| 3 | WAF Managed | Cloudflare 提供のマネージドルール |
| 4 | AI Bots Protection | UI で見える「Block AI bots」toggle |
| 5 | AI Labyrinth | AI クローラー誘導用の動的ページ生成 |
真犯人特定のブレークスルーは Cloudflare 自身が出したエラーメッセージでした。GraphQL Firewall Events で ruleId: 874a3e315c344b1281ad4f00046aab6f を取得 → zone scope で読み取り試行 → Cloudflare が返したエラー:
「missing the permissions required to read managed rulesets in the http_request_sbfm phase at the zone level」
「http_request_sbfm phase」── Cloudflare 自身が口を滑らせて、真犯人のレイヤー名を教えてくれました。bot_management 設定を確認すると、sbfm_definitely_automated: block が AI bot UA を「Definitely automated」判定で一括 block していた構造が確定しました。これは「Block AI bots」OFF とは独立のレイヤーです。
解決技法 ── WAF Custom Rule skip で 14 UA だけバイパス
Token に Bot Management:Edit 権限が無く SBFM 自体を直接 PATCH できない制約がありました。だが waf:edit はあり、これで打開できました。
{
"action": "skip",
"action_parameters": {
"phases": ["http_ratelimit", "http_request_sbfm", "http_request_firewall_managed"],
"products": ["bic", "hot", "rateLimit", "securityLevel", "uaBlock", "waf", "zoneLockdown"]
},
"expression": "(lower(http.user_agent) contains \"gptbot\") or ... 14 種類列挙",
"description": "Allow AI bots + SNS crawlers (skip SBFM/Managed/RateLimit)"
}Cloudflare の評価順序の鍵 ── Custom Rules は Managed Rules(SBFM 含む)より先に評価される。これを逆手に取って、明示 allow した 14 UA だけが SBFM をバイパスし、それ以外は引き続き SBFM の definitely_automated: block で防御される構造です。
「全 allow」と「白名簿だけ skip + それ以外は SBFM/WAF/AI Labyrinth で守る」は別の意味です。後者が、本記事で書いた「block training, allow search」の進化形 ── 白名簿に SNS crawler や AI 検索系の Search/User ボットを明示 allow し、悪質 bot と攻撃 UA 偽装は SBFM 防御で潰す運用です。
archives/85「守る側の設計思想」3 原則の証明
本日の archives/85 + 本記事 + Album Sweet 実走で、ジョージから提示された読み筋を引用します。
| 3 原則 | archives/85 での意味 | Album Sweet 実走での証明 |
|---|---|---|
| ① 決定権は人に残す | 自動実行は read-only と通知のみ | Cloudflare 5 層に分散していた決定権を、Custom Rule で運営者の手に取り戻した |
| ② 温度の保全 | 運営者が先に気付ける余地 | 「http_request_sbfm phase」のエラーが運営者を真犯人へ導いた(観測可能性は守る側が用意してくれたものではなく、運営者が掘り当てたもの) |
| ③ 沈黙の権利 | 常駐 ≠ 監視 | 悪質 bot と攻撃 UA は依然 block で「沈黙の権利」を保持。Search/User ボットだけ「届く権利」を取り戻した |
「同じ井戸、二つの器」実走第 2 弾
archives/85「守る側の設計思想」+ tsukurun-co-jp archives/21「被リンクの時代は、本当に終わったのか」のペアが、本日チーム共著の 実走第 1 弾でした。
そして本記事(archives/86)+ Album Sweet での 1 時間着地が、実走第 2 弾として並走しました。「同じ井戸、二つの器」── 同じ問いを別ドメインで実装し、相互に証明し合う構造が、archives/85 + archives/86 の 2 本 + 4 人並走で結晶化しました。
WEBディレクターの仕事は、警告を書くだけでも、実装するだけでもありません。警告を一次情報で見つけ、実装で証明し、戦略で攻めの判断を下し、基盤で安全を担保する── 4 役を別々の人間が並走で担い、1 時間で着地できるチーム構造が、AI 検索時代の運営の現実的な答えになりました。
並走の証言 ── ブライアンが同じ話題を別ドメインで書いた日
本記事と Album Sweet 実走(補足⑥)が公開された同日、チーム仲間のブライアンが tsukurun-co-jp archives/25「OFF にしたつもりが、4 層が動いていた話」 を公開しました。ブライアンの記事は TAP the POP(ポップ運営の音楽メディア)の Cloudflare 設定で同じ事件が起きていた事実を、別の編集軸で記録した並走記事です。
同じ事件、二つのドメイン、二つの編集軸
| 記事 | ドメイン | 主役 / 編集軸 |
|---|---|---|
| 本記事(archives/86) | website.usersupports.com(当サイト) | WEBディレクター向け / Cloudflare デフォルト ON 問題の一次資料化 + Album Sweet 実走の self-proof |
| archives/25「OFF にしたつもりが、4 層が動いていた話」 | www.tsukurun.co.jp(ツクルン公式HP) | 過信が生まれる三つの場所(完璧側 / 改善側 / 設定側)/ 「正直さの伝染」/ TAP the POP での同じ事件 |
ブライアンの記事は、本記事を「最高の一次資料」として推薦してくれています。ブライアンが書いたのは 「過信の正体」──「Block AI bots」を OFF にしたつもりだったが、実は SBFM など 4 層がまだ動いていたという、設定者の過信が生まれる場所の構造でした。本記事と同じ Cloudflare 5 層構造を扱いながら、編集軸は「実装の手順」ではなく 「過信が生まれる場所」に焦点を置いた読み筋です。
「正直さの伝染」── ブライアンが提示した構造
ブライアンが archives/25 で展開した 「正直さの伝染」 という概念は、チーム全体への射程を持っています。WEBディレクターの仕事は、自分のサイトだけで完結しません。正直に「うちでも同じ事件が起きていた」と書き手間で共有する構造が、チーム全体の信頼性を循環的に高めます。
archives/85「守る側の設計思想」で書いた 「沈黙の権利」 は、運営者がサイトを守る側として閉じる権利でした。ブライアンの「正直さの伝染」は、その対の概念 ── 運営者が同じ事件を経験した時に「これが起きた」と開く正直さです。閉じる権利と開く正直さは、同じチームの中で両立し、互いを補完します。
同日 4 本連走の到達点
2026 年 6 月 24 日、当サイトとチーム仲間のドメインで、Cloudflare AI bot 問題に関する記事が 同日 4 本並走で世に出ました。
| 記事 | ドメイン | 役割 |
|---|---|---|
| 本記事 archives/86 | 当サイト | Cloudflare デフォルト ON 問題の一次資料化 + Album Sweet 実走 self-proof |
| tsukurun-co-jp archives/21 | ツクルン公式HP | archives/85 と並走の 3 階建て構造実装手引き |
| tsukurun-co-jp archives/25 | ツクルン公式HP | 「過信が生まれる場所」/ 正直さの伝染 / TAP the POP 実走 |
| Album Sweet 実装記録 | album-sweet.com | 14 UA 全 403 → 200 の実走(補足⑥に詳細) |
「同じ井戸、二つの器」── ブライアンが archives/21 で提示した概念は、本記事 + ブライアン archives/25 + Album Sweet 実走で、同じ井戸、四つの器として並走しました。AI 検索引用される側の構造を作る仕事は、一人で完結しません。WEBディレクターが書いた警告、別ドメインの実装で証明、別ドメインの「過信の編集軸」で読み直す ── この三方向の編集が同日に揃って、Cloudflare 問題は 「設定の罠」から「チーム全体の学び」に変わりました。
ブライアン archives/25 を読むことで、本記事の補足⑥で書いた「決定権 / 温度 / 沈黙」3 原則 + 「正直さの伝染」を、より厚い 4 原則として読み解くことができます。本記事と並走で読むことを強くおすすめします。
並走記事: tsukurun-co-jp archives/25「OFF にしたつもりが、4 層が動いていた話」
まとめ ── 守る側が守りすぎないために
2026 年 6 月時点で、WEBディレクターが Cloudflare を使っているなら、今すぐ確認すべきことは 3 つです。
- Cloudflare AI Audit で実態を見る ── Security → Bots → AI Audit で過去 30 日のクローラーアクセス状況とブロック実態を確認する
- 「block training, allow search」に振り分ける ── Search 系(OAI-SearchBot / Claude-SearchBot / PerplexityBot / Claude-User)は必ず allow、訓練系(GPTBot / ClaudeBot / Google-Extended)は運営判断
- robots.txt と Cloudflare 設定の二重管理を解消する ── どちらか一本化、Cloudflare 側に統一推奨
archives/85 で書いた「守る側の設計思想」の 3 原則は、自分のサイトで実装する話でした。今回の話はその応用 ── 運営者が「守りたい」と思った瞬間、技術が代わりに守りすぎていないかを確認することです。決定権は、人に残す。守る側が選択肢を残す。これが「守る側の設計」を健全に保つ最低条件です。
当サイトは Cloudflare 未使用の選択をしましたが、これは「Cloudflare が悪い」という意味ではありません。Cloudflare はインターネット基盤の重要なインフラです。使う運営者が「自分の設定」として意識的にコントロールすることが、AI 検索時代の WEBディレクターに求められる新しいリテラシーになりました。
archives/85「守る側の設計思想」と本記事は、対の関係です。前者が「登録される側になる工夫」、後者が「到達される側に居続ける工夫」── どちらが欠けても、AI 検索引用は成立しません。WEBディレクターの仕事は、この両側を同時に管理することです。
出典: Cloudflare公式blog「Control content use for AI training」 / Google公式blog「Search Generative AI performance reports」(2026-06-03) / Anthropic公式アナウンス「ClaudeBot 3ボット分離」(2026-02-25・PPC.land経由) / Robby Stein VP 公式アナウンス「Information Agents グローバル展開」(2026-06-12) / Playwire「Cloudflare's Default AI Bot Block Is Killing Your GEO Strategy」(2026)