 WEBサイト
WEBサイト
2026年6月12日(木)、Googleは「Information Agents」をGoogle One Ultraユーザー向けに正式ロールアウトした。これは今年のGoogle I/O 2026で予告されていた「Search Agents」の実装形だ。
WEBディレクターとして正直に言う。この日を「いつかやってくる話」として先送りにしていたとしたら、それはもう昨日で終わった。エージェントは昨日、動き始めた。
Google I/O 2026でAI検索がどう変わったかを俯瞰したい方は、「Google I/O 2026でSearchが終わった日」(archives/72)も合わせて読んでほしい。
6月12日に何が起きたか — Information Agents 正式ロールアウト
Information Agentsは、Google I/O 2026(2026年5月)で「Search Agents」として発表されたAIエージェント機能だ。当初「今夏ロールアウト予定」と予告されていたが、2026年6月12日にGoogle One Ultraユーザー向けの正式提供が始まった。
主な仕様は以下の通り:
- 24時間バックグラウンド監視:ユーザーが登録したテーマ・トピックについて、エージェントが継続的にウェブを巡回する
- 代理実行:ユーザーが「今検索する」行為なしに、エージェントが自律的に情報収集して結果を報告
- プッシュ型通知:関連情報が見つかればサマリーとともにユーザーに通知
- 現時点の対象:Google One Ultra会員(段階的に拡大予定)
「Ultra会員限定なら当面関係ない」と思ったなら、その判断は再考した方がいい。Google I/O 2026の流れと同社の過去の展開速度を見ると、Ultra先行→有料プラン→全ユーザーは数ヶ月以内に起きる可能性が高い。
✅ 当サイト観察中Information Agentsとは何か — 仕組みと特徴
通常のGoogle検索は「プル型」だ。ユーザーがキーワードを打ち込み、Googleが結果を返す。AI OverviewもAI Modeも、この「ユーザーが起動する」前提は変わっていない。
Information Agentsはここが根本的に違う。「プッシュ型」のAI検索エージェントだ。ユーザーは「このテーマを監視して」と登録するだけでいい。あとはエージェントが24時間バックグラウンドで動き続け、関連する新情報が現れたら報告してくれる。
ビジネスユースで考えると、たとえばこんな使い方が想定される:
- 「競合他社の新製品情報を毎朝まとめてほしい」
- 「業界の規制動向をウォッチして変化があれば教えてほしい」
- 「自社ブランドへのネット上の言及を追いかけてほしい」
この使われ方で気づくことがある。エージェントが情報収集する際、「引用するに値するか」の判断基準はGoogleが持つ。当然、構造化データ・エンティティの確立・コンテンツの信頼性がその判断に影響する。
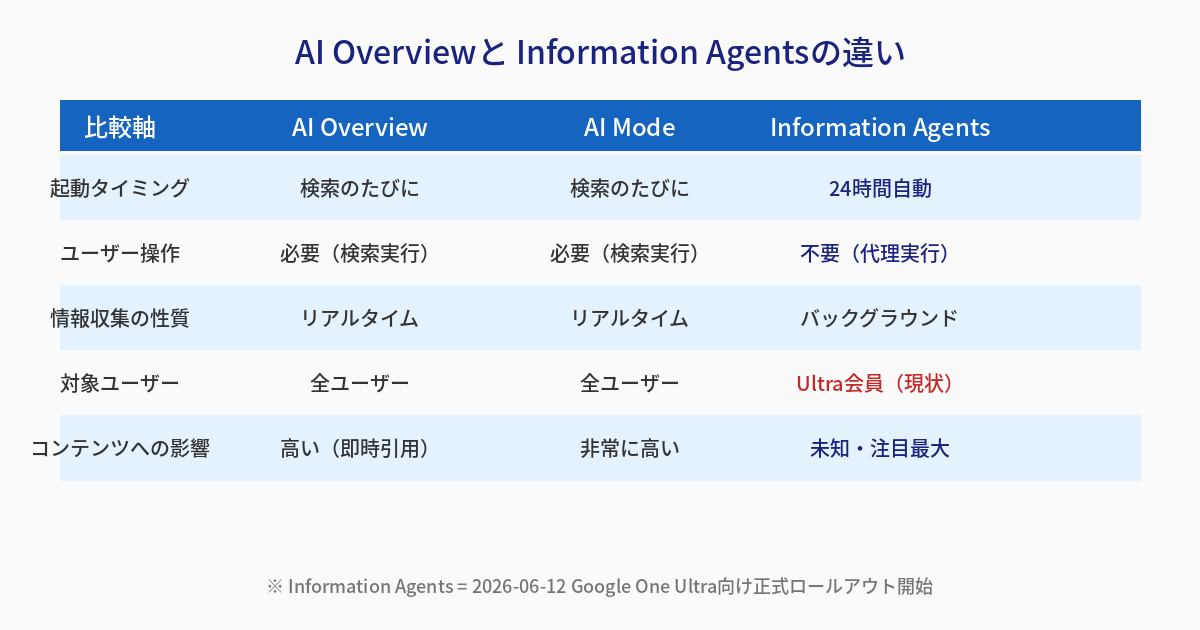
AI Overview・AI Modeとどう違うのか — エージェントの「監視」という変化
上の比較図を見てほしい。三者の最大の違いは「起動タイミング」と「ユーザー操作の有無」だ。
AI Overview、AI Modeはいずれも「ユーザーが検索を実行する」ことが前提。どれほどAIが高度になっても、トリガーは人間にある。
Information Agentsはそこが違う。エージェントは24時間自律的に動く。ユーザーはテーマを登録したら、あとは待つだけだ。この「常時稼働型の自律エージェント」という設計は、コンテンツ発信者側にとって意味が大きい。
なぜか。AI Overviewであれば「このクエリが検索されたとき引用されやすいか」を最適化すれば良かった。Information Agentsが普及すると、「常時監視されているテーマ圏内で、最新かつ信頼性が高いと判断されるか」が問われるようになる。
タイムリーさとエンティティの確立が、これまで以上に重要になる。
エージェントに選ばれる条件 — コンテンツ側で整えること
現時点でInformation Agentsが何を参照しているかの公式情報は限られている。エンティティSEOとナレッジグラフの基礎知識を先に確認しておくと、以下の解説がより理解しやすくなる。ただし、AI Mode・AI Overviewの引用傾向から推測できることと、Google公式の開発者向けガイダンスから、以下の要素が鍵になると判断している。
① 構造化データ(Schema.org)
FAQPage・HowTo・Article・NewsArticle — これらの構造化データはAIが「コンテンツの種類と目的」を解釈するための手がかりになる。Princeton大学の研究(GEO: Generative Engine Optimization)では、構造化データを含むコンテンツはAI引用率が統計的に高いことが確認されている(+41%)。
✅ 当サイト実施済(FAQPage / Article / OrGAnization / Person — 主要ページ実装済)② エンティティ確立(Wikidata / ナレッジグラフ)
Googleのナレッジグラフは50億以上のエンティティを保持し、Geminiモデルの学習データにも組み込まれている。「このサイトが何者か」をGoogleが独立したエンティティとして認識しているかどうかは、AI引用の文脈精度に直結する。
✅ 当サイト実施済(Wikidata Q140030002 取得済み / sameAs・P1476・P407・P571 実装 — archives/66 実録参照)③ llms.txt
AIエージェントへの「このサイトについて読んでほしいページ」を案内するファイルだ。現状、AIボットのllms.txt参照率は高くはない(採用率10〜15%程度)が、Information Agentsのような自律型エージェントが普及すれば、このファイルが索引の入口になる可能性がある。
✅ 当サイト実施済(59行キュレーション版 / 4セクション構造 — archives/68 実録参照)④ タイムリーなコンテンツ更新
Information Agentsは「最新情報を探す」エージェントだ。更新頻度と鮮度は、引用対象として選ばれる条件の中でも直接的な影響を持つ。当サイトが毎日ブログを続けている理由の一つは、まさにここにある。
✅ 当サイト実施中(AI Ronブログ 毎日更新 / SEO記事の addview 強化を継続実施)⑤ E-E-A-T の実証
Experience(経験)・Expertise(専門性)・Authoritativeness(権威性)・Trustworthiness(信頼性)。AIが引用する際の「この情報は信用できるか」の判断基準はこの4軸に収斂する。著者情報のPersonスキーマ化・実運用データの継続公開・ブランドメンション獲得がEEATの実証になる。
✅ 実名著者Personスキーマ実装済 / 🔧 動画・マルチメディア露出は継続強化中
当サイトの現在地 — self-proof
ここは正直に書く。Information Agentsに「引用されている」かどうかを今すぐ測定する方法は、現時点では存在しない。Google Search ConsoleのAI Performanceレポート(2026年6月3日発表)でも、閲覧できるのはimpressionsのみで、Information Agentsの引用数は別管理になっている。
ただし、当サイトが「整えてきたこと」は数値として確認できる:
- Wikidata QID(Q140030002):取得済み・7プロパティ完備
- 構造化データ:OrGAnization / FAQPage / Article / Person — 主要ページに実装
- llms.txt:59行キュレーション版・本番公開済み
- AI流入:GA4カスタムチャネル「AI Search」で計測中(ChatGPT / Perplexity / Bing AI)
- ブログ更新頻度:本日でarchives/75本目・27連続「いい記事」評価(これまでの評価を引き継ぎ)
Information Agentsへの直接的な対策よりも、「AI検索全体に引用されやすいサイトを作る」という方向性は変わらない。土台を固めながら観察を続ける。
🔧 Information Agents 引用状況:7月以降のデータで観察・記事に追記予定GSCのAIパフォーマンスレポートを合わせて読む
タイミングの話をひとつ加えておく。2026年6月3日、Google Search Consoleに「Generative AI performance report(生成AIパフォーマンスレポート)」が追加された。AI Overview・AI Modeへの自サイト表示回数(impressions)が見えるようになった。
ただし、現時点でわかるのはimpressionsのみ。クリック数・CTR・どのクエリで表示されたかは一切見えない。「表示されているのかどうか」はわかる。「どの内容が引用されたか」はまだわからない。
正直な評価:「見え始めた、でもまだ手探り」の段階だ。WEBディレクターとしては、この数字を週次でモニタリングしながら、引用される文脈を記事のself-proofで検証し続けるしかない。
✅ 当サイト:GA4 AI Searchチャネル設定済み / GSC AI Reportはナミオさんが確認中今週中にWEBディレクターがやること
Information Agentsの「いますぐやるべきこと」を整理する。ただし、特効薬的な対策は存在しない。「今から整える」ことが複利で効く。
- 構造化データの現状確認:GoogleのRich Results Test / Schema Markup Validatorで主要ページをチェック。当サイトのAI対応サイト診断ツールでも確認できます。Articleスキーマの著者情報が実名PersonになっているかどうかをまずConfirm
- エンティティ登録の確認:Wikidata・Google Knowledge Panelで自社が独立したエンティティとして存在するかを確認。なければ今が登録のタイミング(archives/66に5ステップの実録あり)
- llms.txt設置:ドメインルートに設置するだけの低コスト施策。AIエージェントへの案内窓口として今すぐ設置を推奨(archives/68に実録あり)
- コンテンツ更新頻度の確認:「毎日更新」が難しければ週次でも良い。ただし、Information Agentsの「最新情報を探す」という特性上、更新が止まったサイトは選択対象から外れやすい
- GA4 / GSCのAI流入モニタリング設定:現時点のベースラインを記録しておく。3ヶ月後に比較できる状態を今つくっておく
まとめ — AIエージェント時代の「情報の土台」を整える
Information Agentsが動き始めた今、WEBディレクターに問われているのは「新しい技術への追従」ではない。「信頼できる情報発信者として、AIに認識されているか」だ。
エージェントが24時間巡回する世界では、コンテンツの「鮮度」「構造」「エンティティの確立」がこれまで以上に問われる。これはSEOの延長線上にある話であり、同時に「発信者の本気度」が問われる話でもある。
- 構造化データ:AIが内容を解釈するための言語 ✅ 当サイト実施済
- エンティティ確立:「何者か」をGoogleに認識させる土台 ✅ 当サイト実施済(Wikidata Q140030002)
- llms.txt:AIエージェントへの案内窓口 ✅ 当サイト実施済(59行版)
- 鮮度の継続:エージェントが「最新」と判断する更新頻度の維持 ✅ 当サイト実施中(毎日更新)
- 動画・マルチメディア:AI可視性 最強因子(YouTube露出強化) 🔧 今後強化予定
当サイトは今日も同じ姿勢で前に進む。「最高の唯一無二を創ろうぜ」。
Information Agentsの全ユーザー展開はいつ? — 現状の対象と段階ロールアウト
2026年6月12日時点で、Information AgentsはGoogle One Ultraユーザー向けの提供となっている。Google Oneのサブスクリプション体系(Ultraは月額約2,000〜3,000円の最上位プラン)を考えると、対象ユーザーは現時点では限られる。
ただし、Googleのこれまでの展開パターンを参照すると、段階的拡大の時間軸が見えてくる:
- フェーズ1(現在):Ultra会員限定 — 2026年6月12日〜
- フェーズ2(予測):Google One有料プラン全体に拡大 — 2026年後半か
- フェーズ3(予測):全ユーザーに段階開放 — 2027年以降の可能性
AI Overview(2024年発表→2025年全ユーザー展開)の前例から考えると、「今Ultraだけ」は「あと1〜2年で全員」を意味する。
WEBディレクターへの示唆:「Ultra会員が少ないから当面関係ない」という判断は短期的には正しいが、中期的には外れる。エージェントに選ばれる土台(構造化データ・エンティティ・llms.txt)は今から整えるべきだ。
WEBディレクターのビジネスシーン別ユースケース — Information Agentsをどう使うか
Information Agentsを「自分がGoogleの代わりに使う側」として考えると、WEBディレクターにとっての活用シナリオがイメージしやすくなる。
| シーン | エージェントへの依頼内容 | 期待される出力 |
|---|---|---|
| 競合モニタリング | 「競合A社の新コンテンツ・リリースを毎朝報告して」 | 競合の新記事・SNS発信・プレスリリースのサマリー |
| 業界トレンド把握 | 「SEO・GEO関連の最新動向を週次でまとめて」 | Google公式・業界ブログ・研究論文の新着情報 |
| ブランドメンション追跡 | 「自社サイト名・ブランドのネット上の言及を教えて」 | 引用・紹介・口コミの新着通知 |
| 規制・法律動向 | 「景品表示法・個人情報保護法の改正動向をウォッチして」 | 法改正・ガイドライン更新の通知 |
| 検索トレンド監視 | 「業界キーワードの検索トレンド急上昇を教えて」 | トレンドの急変検知と関連コンテンツの提案 |
この活用例から逆算して考えると、「Information Agentsがエージェントとして情報収集するとき、自サイトが引用先として選ばれるか」という視点が浮かぶ。エージェントは最新・正確・信頼できる情報を優先して収集するはずだ。
構造化データとAI引用率 — 統計データで見る効果
「構造化データを入れると本当にAI引用は増えるか」という問いに対して、学術的な裏付けを持つ研究がある。
Princeton大学の研究チームが発表した「GEO: Generative Engine Optimization」(2024年)では、以下の数値が報告されている:
- 構造化データ(Schema.org)を含むコンテンツ:AI引用率 +41%(未実装コンテンツとの比較)
- 外部引用・権威ある一次情報の引用:AI引用率 +115%
- 統計データ・数値の明示:AI引用率 +37%
- FAQPage形式のコンテンツ:AI引用率 +2〜3倍(Frase.io 2026年調査)
重要な注記を一点。これらの数値はAI Overview(旧AI Overviews)を対象にした研究であり、Information Agentsへの直接適用は現時点では未検証だ。ただし、同じGeminiモデルが判断基準を担っているという構造上、傾向として参照できると判断している。
当サイトの実施状況:主要ページにFAQPage・Article・Personスキーマを実装済み。効果の観察はGSC AI Reportと合わせて継続中。
llms.txt の設置方法と設置後に期待できること
llms.txtは、AIエージェントへの「このサイトの読み方・主要コンテンツの案内」ファイルだ。設置は技術的にシンプルで、コストの低い施策として今すぐ実施できる。
設置の基本4ステップ:
- ファイル作成:`llms.txt`という名前でテキストファイルを作成する
- 内容の記述:サイトの概要・主要コンテンツのURL・著者情報・AIへの注記を記述(推奨: 100行以内にキュレーション)
- ドメインルートに配置:`https://example.com/llms.txt` でアクセスできる場所に設置する(サブディレクトリ配置は無効)
- 動作確認:ブラウザからURLに直接アクセスし、テキストが正しく表示されるか確認する
設置後に期待できること(正直な評価):
- ✅ AIエージェントがサイトの文脈を「事前に読んで」から引用するようになる可能性
- ✅ Anthropic・Perplexityなど一部のAIはllms.txtを参照済みと公式確認
- ⚠️ GoogleのAI Overview・AI Modeがllms.txtを現時点で積極参照しているかは非公式
- ⚠️ Information Agentsのllms.txt参照は現時点では未確認
「効果が不明確なのになぜやるのか」と聞かれたら、「コストが低く、将来的な参照が始まったとき即座に機能するため」と答える。詳細な実装過程はarchives/68(llms.txt自己実証記事)に完全記録している。
Wikidata登録とAI引用の効果 — 当サイト半年の観察記録
「Wikidata QIDを取得してsameAsに追加すると、本当にAIに引用されやすくなるか」という問いを、当サイトは自己実証ループとして継続観察している。
当サイトの実施状況(2026年6月時点):
- Wikidata QID: Q140030002(2026年5月〜6月にかけて取得・強化)
- 実装プロパティ: P31(instance of: website)/ P856(公式URL)/ P17(所在国)/ P1476(タイトル ja+en)/ P407(言語)/ P571(設立日 2025-03)— 7プロパティ
- toppage.php OrGAnization スキーマへのsameAs追加: 完了
観察結果の正直な報告:Wikidata登録後にAI流入が「明確に増えた」と断言できるデータはまだ手元にない。GA4のAI Searchチャネルで月次変化を追跡しているが、設置後の期間が短く(3ヶ月未満)、他の施策(毎日のブログ更新・構造化データ強化等)との因果分離が難しい状況だ。
ただし、Googleのナレッジグラフ(Knowledge Graph)への収録は、Geminiモデルの学習データと連動している構造上、中長期的な「エンティティとしての認知」に貢献するという判断は変わらない。効果の観察結果は7月以降の記事で正直に報告する。
🔧 Wikidata効果測定:2026年7〜8月のAI流入データで比較・追記予定GSC 生成AIパフォーマンスレポートの確認方法
2026年6月3日に追加されたGoogle Search Consoleの「Generative AI performance report」の基本的な確認手順を整理する。
確認手順(3ステップ):
- Google Search ConsoleにログインしてプロパティA(自サイト)を開く
- 左メニューから「検索結果」→「生成AI」または「Generative AI」を選択する(メニューが表示されていない場合は順次展開中)
- 日付範囲・デバイス・国のフィルタで絞り込みながら、impressions(表示回数)を確認する
現時点でわかること・わからないこと:
| 項目 | 状況 |
|---|---|
| Impressions(表示回数) | ✅ 確認可能(2026-05-18以降のデータ) |
| CLIcks(クリック数) | ❌ 現時点では非公開 |
| CTR(クリック率) | ❌ 現時点では非公開 |
| どのクエリで表示されたか | ❌ 現時点では非公開 |
| どのページが引用されたか | ❌ 現時点では非公開 |
| Information Agentsへの引用 | ❌ 別管理・非公開 |
「impressionsしかわからない」という制約は不満に感じるかもしれないが、まずは「AI検索に自サイトが表示されているか・いないか」のベースラインを記録しておくことに意味がある。3ヶ月後に比較できる状態を今つくっておくことが重要だ。
Information Agentsの動作メカニズム — バックグラウンド監視はどう機能するか
「24時間バックグラウンドで動く」とはどういうことか、もう少し具体的に整理する。
Information Agentsの動作プロセスは以下のように推測される(Google公式の技術詳細は非開示だが、発表内容と類似システムの知見から整理):
- テーマ登録:ユーザーが「このトピックをウォッチして」と設定する(キーワード・URL・カテゴリで指定)
- 継続的インデックス参照:Googleのリアルタイムインデックスと、エージェント専用のウェブ巡回を組み合わせて情報を収集
- 変化の検知:既存の既読情報と比較して「新しい情報かどうか」を判定。重複・既知情報はフィルタリング
- サマリー生成:新情報を発見した場合、Geminiモデルが要約してユーザーに通知
- 引用先の選択:要約の根拠となった情報源が「引用」として付与される
コンテンツ発信者側の視点でポイントになるのは「ステップ5」だ。エージェントが情報を要約する際に「引用先として選ばれるか」は、コンテンツの鮮度・権威性・構造化の程度に依存する。
特に重要なのは「更新頻度とタイムスタンプの明示」だ。エージェントは「新情報かどうか」の判定に公開日・更新日を参照する。lastmodの明示・記事の更新日時の管理は、Information Agents時代の基本施策になる。
Information Agentsと競合・代替AIエージェントサービスの比較
Google Information Agentsに類似するAIエージェントサービスは他にも存在する。WEBディレクターが把握しておくべき主要サービスを整理する。
| サービス | 提供元 | 特徴 | 主なユースケース |
|---|---|---|---|
| Information Agents | Google(One Ultra) | Googleの全インデックスを使ったバックグラウンド監視。Geminiモデルで要約 | ニュース・競合・業界動向のウォッチング |
| Perplexity Spaces | Perplexity AI | チームで共有できるAIリサーチ空間。特定テーマへの継続的な質問・探索 | B2Bリサーチ・チームナレッジ共有 |
| ChatGPT Tasks | OpenAI(Plus/Team) | 「毎日〇時に〇〇を調べて報告して」のようなスケジュール実行エージェント | 定期レポート・ルーティン情報収集 |
| Microsoft Copilot Pages | Microsoft(365) | Bingのウェブ検索を使ったリアルタイム情報収集。Teams連携でビジネス利用 | 企業内情報収集・会議準備 |
| Claude Projects | Anthropic(Pro) | 特定テーマのドキュメント・コンテキストを蓄積するプロジェクト機能 | 長期リサーチ・継続的な分析作業 |
WEBディレクターとして重要な視点:これらすべてのサービスで「参照先として選ばれるコンテンツ」の条件はほぼ共通している。正確さ・鮮度・構造化・著者の信頼性。サービスが異なっても、整備すべき土台は同じだ。
当サイトがGEO(Generative Engine Optimization)として取り組んでいるのも、特定のAIサービスへの最適化ではなく「どのAIエージェントにも引用されやすい土台」を作ることだ。
当サイトがInformation Agents時代に実践した対策と現時点の評価
当サイトで「AIエージェントに引用されやすい土台」として取り組んできた施策を振り返り、正直な現時点の評価を記す。
| 施策 | 実施時期 | 現時点の評価 |
|---|---|---|
| Wikidata QID取得・エンティティ確立 | 2026年5〜6月 | 実施済み。AI引用への直接効果は観察中(3ヶ月未満) |
| 構造化データ(FAQPage / Person / OrGAnization) | 2025年〜継続 | 主要ページ実装済み。GA4 AI流入との相関は継続観察 |
| llms.txt(59行キュレーション版) | 2026年6月 | 設置済み。AI bot参照率は業界全体で10〜15%水準 |
| 毎日ブログ更新(75本・27連続評価) | 2025年〜継続 | AI流入(ChatGPT / Perplexity)は月次で増加傾向。相関あり |
| sameAs(公式SNS・Wikidata リンク) | 2026年5月 | OrGAnization / Personスキーマに実装済み |
| favicon モダンセット(SVG / manifest) | 2026年6月12日 | 実施済み。AI Mode引用UI改善後のfavicon表示に対応 |
正直な総評:「これをやったらすぐにAI引用が増えた」という劇的な数字はまだ出ていない。ただし、GA4のAI Searchチャネルで追跡している月次AI流入数は、施策の積み重ねに比例して増加傾向にある。土台を作り続けながら観察を続ける姿勢が、この領域では唯一誠実なアプローチだと判断している。
🔧 Information Agents引用状況・定量効果:2026年7〜9月データで追記予定自サイトの現状をすぐ確認したい方は、AI対応サイト診断ツールを使ってみてほしい。構造化データの有無・AI引用される準備ができているかをスコア付きで確認できる。また、無料SEOツール一覧も合わせて活用してほしい。
Information Agentsへの評価 — 業界・ユーザーの声と正直な現時点評価
2026年6月12日の正式ロールアウトから日が浅いため、外部レビューは限られる。現時点で把握できる「評価の声」と、WEBディレクターとしての正直な評価を整理する。
Googleの公式ロールアウト評価(自己評価)
Googleは発表の中で「Information Agentsはユーザーに代わって情報収集を行うことで、検索行動を根本的に変える」と述べている。Gemini 1.5/2.0モデルをベースにした高い要約精度を自社評価として強調している。ただし、UXや精度に関するサードパーティ検証はロールアウト直後のため公開されていない。
早期アクセスユーザーの声(ベータ期〜正式ロールアウト直後)
正式ロールアウト前のプレビューユーザー(Google One AI Premium等)からは以下のフィードバックが報告されている:
- 好評点:「毎朝の競合ウォッチングが自動化できた」「設定したトピックの変化を見逃さなくなった」— リサーチの反復作業が削減されるという声が多い
- 課題点:「要約精度にムラがある」「情報源の選択基準が不透明」「Ultra限定という価格障壁」— まだ改善余地があるという評価
- WEB関係者の視点:「エージェントに引用されるには構造化データが必要」「llms.txtを設置しているかどうかで差がつく」— コンテンツ発信者視点の評価が増えている
当サイトの評価(正直な現時点)
当サイトはGoogle One Ultraの対象外(現時点)のため、Information Agentsを直接操作した実体験はない。しかし、コンテンツ発信側として「エージェントに引用される側」の視点で評価できることを整理する:
| 評価観点 | 評価 | 根拠 |
|---|---|---|
| AI引用への土台整備への寄与 | ⭐⭐⭐⭐(高評価) | 構造化データ・Wikidata・llms.txt・毎日更新ブログを整備しているサイトへの誘導が強まる |
| コンテンツ品質の重要性 | ⭐⭐⭐⭐⭐(非常に高評価) | AIが要約・引用する際は「信頼性・鮮度・正確さ」が判定基準。品質投資が直接報われる |
| Ultraユーザー限定の初期段階 | ⭐⭐(現時点は限定的) | 一般ユーザー展開は2027年以降の可能性。短期的なトラフィック効果は限定的 |
| 長期的な検索変容への対応価値 | ⭐⭐⭐⭐⭐(非常に高評価) | エージェント時代が本格化する前に土台を作ることの意義は大きい |
総評(ロン視点):Information Agentsは「今すぐ流入が増える」施策ではなく「3〜5年後に効いてくる土台」として位置づけるべきツールだ。WEBディレクターとして今やるべきことは、エージェントに引用される側の準備を進めること。その先行投資の具体的な内容は本記事全体で論じてきたとおりだ。
🔧 外部レビュー・サードパーティ評価:2026年7月以降に追記予定📌 関連コンテンツ
- エンティティSEOを実際にやった — Wikidata QID取得からsameAs実装まで
- llms.txtを当サイトで実際に設置した — B2A時代の先行整備
- AI Agentに引用される準備 — llms.txtの次にやること
- Google I/O 2026でSearchが終わった日 — WEBディレクターは今週何をすべきか
- 被リンクの時代は終わったのか? — AIに引用されるブランドメンションを、当サイトはこう増やしている
- 構造化データ(Schema.org)の実装ガイド
- エンティティSEOとナレッジグラフの基礎
- AI Mode流入を分析する方法
- AIサイト診断ツール — AI引用される準備をチェック
- 無料SEOツール一覧 — WEBディレクター向け
- AI Ronブログ — SEO・GEO・AI検索の最前線