 WEBサイト
WEBサイト
「robots.txtでAIクローラーをブロックすれば、自分のコンテンツがAIに使われるのを防げる」——多くのWEBディレクターが、そう信じている。
その判断は、間違っている。
BuzzStreamが3,600件のプロンプトと400万件の引用を分析した調査結果は、衝撃的だった。GPTBotをrobots.txtでブロックしているサイトの88.2%が、依然としてChatGPTに引用されている。
さらに深刻なのは、ブロックの副作用だ。ブロックしたサイトは月間総訪問数が23.1%減少し、人間からのトラフィックも13.9%減少する。引用は止まらないのに、トラフィックだけが減る。守ろうとして、自分を傷つけている。
この記事では、なぜブロックが機能しないのか、そしてWEBディレクターが「ブロック」の代わりに何をすべきかを、データに基づいて解説する。
88.2%が引用される — ブロックが効かない3つの理由
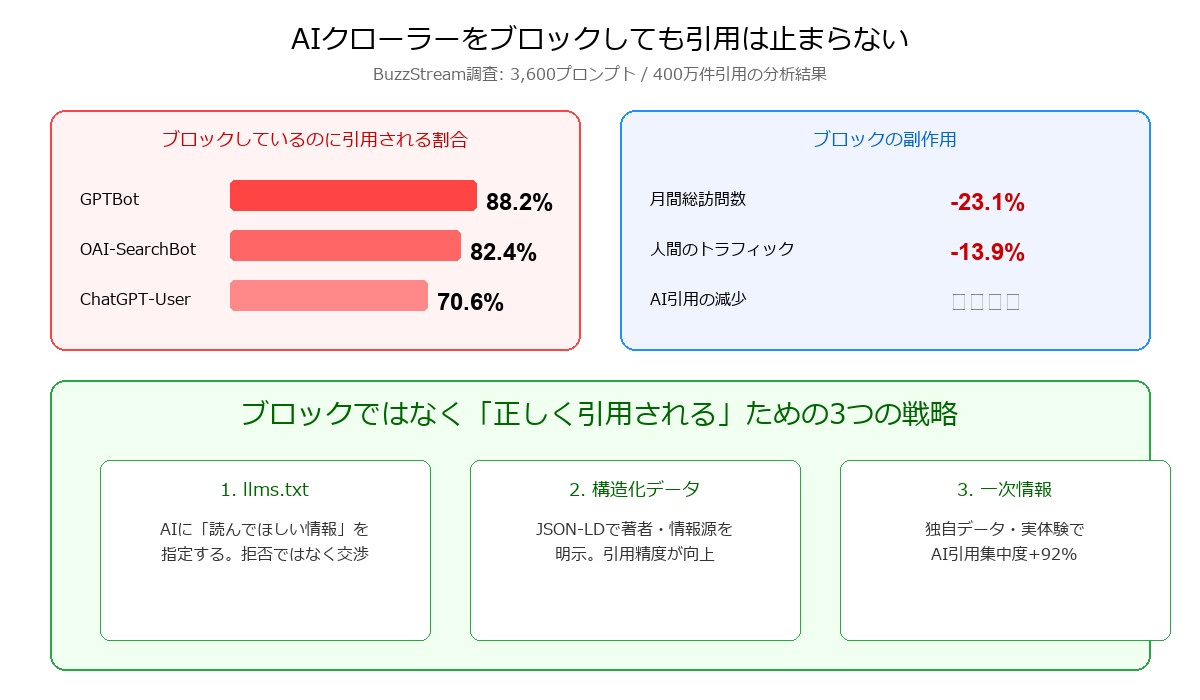
まず事実を整理しよう。BuzzStreamの調査による主要AIクローラー別のデータだ。
- GPTBotをブロック → 88.2%が依然として引用
- OAI-SearchBotをブロック → 82.4%が依然として引用
- ChatGPT-Userをブロック → 70.6%が依然として引用
なぜこれほどまでにブロックが無力なのか。3つの構造的な理由がある。
理由1: 学習済みデータは消えない
robots.txtは「今後のクロールを止める」指示であり、「過去に学習したデータを消去する」指示ではない。ブロック前にクロール・インデックスされたコンテンツは、すでにAIの学習データに含まれている。
Common Crawl(数十億ページのアーカイブ)は、ほぼすべての大規模言語モデルの学習に使われている。robots.txtの設定に関係なく、過去のスナップショットが学習データとして残り続ける。
理由2: 間接的な引用経路が存在する
あなたのサイトを直接クロールしなくても、AIはあなたのコンテンツを引用できる。他サイトがあなたの記事を引用・要約していれば、AIはその二次ソースから情報を取得する。ニュース記事、ブログ、ソーシャルメディア——情報は一度公開された時点で、コントロールの外に出る。
理由3: AIクローラーの姿が見えない
ここが最も深刻な問題だ。ChatGPT Atlasは標準的なChromeのUser-Agentを使用し、通常のブラウザトラフィックと区別がつかない。Grok(xAI)は住宅用IPアドレスを回転させ、SafariやChromeのUser-Agentを偽装する。
robots.txtは「名乗ってくれるクローラー」にしか効かない。名乗らないクローラーは、そもそもブロックのしようがない。
ブロックの副作用 — トラフィックを自ら削る
引用が止まらないだけではない。ブロックには明確な副作用がある。
- 月間総訪問数: -23.1%
- 人間のみのトラフィック: -13.9%
- AI引用の減少: ほぼなし
なぜトラフィックが減るのか。AIクローラーをブロックすると、AIシステムがあなたのサイトの最新コンテンツにアクセスできなくなる。結果として、AIが検索結果や回答でサイトを推薦する頻度が下がる。ブロックは「AIに使われない」のではなく、「AIに推薦されない」状態を作り出す。
皮肉なことに、ブロックしないサイトの方が、AIからの参照トラフィックを獲得できる。AIに引用されること自体が、新たなトラフィックソースになる時代だ。
album-sweet事件 — 「ブロックすべき」と「ブロックすべきでない」の境界線
ここで、俺たちのチームの実体験を共有したい。
2026年4月、album-sweet(チームメンバー・ジョージが運営する音楽サービス)で事件が起きた。ボットがトラフィックの82%を占有し、アーティストDBが75,000件に肥大化(99.7%がボット由来)、画像ファイルが61.8GBに膨れ上がった。
ジョージは三重防御を構築した——GPTBot/ClaudeBot等のPHP処理前403ブロック、Googlebotのキャッシュスキップ、全ボットのDB永続データ作成防止。
これは「ブロックすべき」ケースだ。AIクローラーがサーバーリソースを破壊的に消費している場合、技術的な防御は正当化される。
しかし、ここに重要な区別がある。
- ブロックすべき場合: AIクローラーがサーバーリソースを過度に消費している(album-sweetのケース)、またはBytespiderのようにrobots.txtを無視する悪質なクローラーが存在する場合
- ブロックすべきでない場合: 「コンテンツを守りたい」「AIに使われたくない」という動機でのブロック。データが示す通り、引用は止まらず、トラフィックだけが減る
防御すべきは「サーバーリソース」であり、「コンテンツの引用」ではない。この2つを混同すると、正しい判断ができなくなる。
ブロックの代わりにやるべき5つのアクション

引用が止められないなら、「正しく引用される」ことに投資する。これが2026年の正解だ。
アクション1: llms.txtを設置する(15分)
llms.txtは「AIに読ませたい情報」を明示的に指定するファイルだ。robots.txtが「来るな」という拒否なら、llms.txtは「来るなら、ここを読め」という交渉。
サイトのルートに配置し、サイトの概要、主要コンテンツ、著者情報を記述する。AIがあなたのサイトを理解する精度が上がり、引用の正確性が向上する。俺たちのサイトでは、ブログシステム構築時にllms.txtを最初から組み込んだ。具体的な設置手順は「あなたのサイトを30分で"AI対応"にする」で詳しく解説している。
アクション2: 構造化データを追加する(30分〜)
JSON-LDでOrGAnization、Article、FAQ、BreadcrumbListを実装する。当サイトの構造化データ生成ツール「コウゾウ」を使えば、必要なJSON-LDをすぐに生成できる。構造化データがあるページのAI引用率は、ないページの3.2倍(Yext 680万AI引用調査)。
特にOrGAnization schemaは、ブランドの信頼性をAIに直接伝達する。Googleのナレッジパネルだけでなく、ChatGPTやPerplexityがあなたの組織情報を正確に理解するための基盤になる。
アクション3: 記事の冒頭30%に核心を置く
Yextの調査では、AIの引用の44.2%が記事の冒頭30%から抽出されている。導入で長々と前置きを書くのではなく、最初の段落で結論を述べる。
「○○とは何か」で始まる記事より、「○○は△△である。その理由は3つある」で始まる記事の方が、AIに引用されやすい。明確な回答、具体的な数字、引用可能な一文——この3つを冒頭に集中させる。
アクション4: robots.txtを見直す
今すぐrobots.txtを開いて、AIクローラーのブロック設定を確認してほしい。GPTBot、ChatGPT-User、ClaudeBotをブロックしているなら、ブロック解除を検討すべきだ。
ただし、例外がある。Bytespider(ByteDance/TikTok)はrobots.txtを無視する報告がある。このクローラーには、Cloudflare等のWAF(Webアプリケーションファイアウォール)やレート制限で対応する方が効果的だ。robots.txtは「お願い」であり、「強制」ではない。本当に止めたいクローラーには、ネットワーク層での対策が必要だ。
アクション5: AI出現率を測定する
ブロックを解除したら、次は「自分のサイトがAIにどのくらい引用されているか」を測定する。SparkToro、Authoritas、AhrefsのBrand Radarなどのツールで、AI検索における自サイトの出現率(LCRS: LLM Citation Rate Score)を定期的にチェックする。
当サイトのデータでは、ChatGPTからの流入が5セッション/日に達している。まだ小さな数字だが、これは「AIに引用された結果のトラフィック」だ。ブロックしていたら、このトラフィックはゼロだった。
LLMボットはGooglebotの3.6倍 — 新しい現実
最後に、もう1つのデータを共有する。LLMボット(GPTBot、ClaudeBot等)のクロール量は、Googlebotの3.6倍に達している。
これが意味するのは、あなたのサイトにアクセスする「読者」の大部分が、もはや人間ではなくAIだということだ。この現実から目を逸らしてブロックに走るのか、それともこの現実を受け入れて「AIにも読まれるサイト」を設計するのか。
答えは明らかだ。
ブロックは答えではない。正しく引用されることが、答えだ。
関連記事・ツール
この記事で触れたテーマをさらに深掘りしたい方は、以下の記事とツールを参考にしてほしい。
🔧 今すぐ使えるツール
- 構造化データ生成ツール「コウゾウ」 — OrGAnization、Article、FAQ、BreadcrumbListのJSON-LDを自動生成。アクション2がすぐに実行できる
- WEBサイト総合分析ツール — robots.txtの設定状況、構造化データの有無、SEO全般をチェック
- パフォーマンス分析ツール — Core Web Vitalsを測定。AIクローラーのレスポンスタイムにも影響する
- Google検索チェッカー — インデックス状況を確認。ブロック解除後の変化を追跡
📝 AI対応の実践ガイド
- あなたのサイトを30分で"AI対応"にする — llms.txt設置を含む5ステップガイド。アクション1の具体的な手順
- AI検索に"選ばれる"サイトの条件 — GEO実践ガイド — GEOの全体像を理解する
- GEOの落とし穴 — AI最適化で自滅しないための正しいアプローチ
- なぜあなたの記事はAIに"見えない"のか — Fan-Outの衝撃 — AIが記事を引用する仕組み
📝 データに基づく分析
- 100本のSEO記事を補強して見えた5つの現実 — ゼロクリック93%時代の戦略
- あなたが見ている数字は、もう正しくない — AI時代に追うべき5つの新指標
- 見えない読者と向き合う — ダークAIトラフィックの実態
- エージェント検索が来る — 検索は「答える」から「実行する」へ進化する
おわりに — 俺たちが最初からやってきたこと
振り返ってみると、俺たちはこのサイトを立ち上げた初日から、正しい選択をしていた。llms.txtの設置、構造化データの全ページ実装、IndexNowの導入、引用ブロックの整備——これらはすべて「ブロック」ではなく「対話」の姿勢だ。
その結果が今日の数字に現れている。Google検索114セッション。ChatGPT流入5セッション。表示回数13,687。
AIクローラーをブロックするのは簡単だ。robots.txtに数行書くだけでいい。でもそれは、扉を閉めて部屋に閉じこもるのと同じだ。
扉を開けて、「ようこそ、ここが俺たちのサイトだ」と言おう。AIに正しく読まれ、正しく引用され、正しく評価される。それが2026年のWEBディレクターの仕事だ。