 WEBサイト
WEBサイト
2026年5月15日、Google Search Centralが静かに、しかし明確に宣言した。
「AI検索への表示のために、新しい機械可読ファイル・AI用テキストファイル・専用マークアップは不要です。」
これはllms.txtへの死刑宣告だった。少なくとも、Google向けには。
この記事では、Googleの公式ガイドが何を言い、何を言っていないかを整理し、当サイトのLCRS測定データを交えながら、WEBディレクターが今週どう動くべきかを考える。
llms.txtとは何か ── 定義・構造・誕生の経緯
まず前提を整理する。llms.txtとは、2024年にAI研究者のJeremy Howard(fast.ai創設者)が提唱したMarkdown形式のテキストファイルだ。サイトのルートドメインに置き、LLMがコンテンツを効率的に把握できるよう設計されている。
ファイルの基本構造はシンプルだ。
# サイト名
> サイトの概要・目的(1〜2文)
## コンテンツ一覧
- [ページ名](/page.md): ページの説明
- [APIドキュメント](/api-docs.md): API仕様の説明
## 除外
llms-full.txtで学習対象外コンテンツを指定可能
もともとの想定用途は「LLMのコンテキスト窓に収まる形で、サイトのコンテンツ概要を機械可読に提供すること」だ。代表的な企業がどう実装しているか確認しておく。
| 企業 | llms.txtの用途・記述内容 | 主な目的 |
|---|---|---|
| Anthropic | Claude・APIドキュメント・Acceptable Use Policyへの構造化されたリンク一覧 | Claude自身がAnthropic社のポリシーを正確に参照できるようにするため(自己参照型の品質管理) |
| Stripe | Payments API・Webhooks・SDKリファレンスの全エンドポイントへのMarkdownリンク集 | 開発者がCursor・GitHub CopilotなどIDEエージェントを使ってStripe APIを実装する際の精度向上 |
| Cloudflare | Workers・D1・R2などエッジ製品のドキュメントURL一覧。`llms-full.txt`でフル版も公開 | 開発者エコシステムでのブランド認知強化と、AIアシスタントによるコード補完精度向上 |
| Supabase | Database・Auth・Storage APIドキュメントの構造化リスト | 開発者向けIDEエージェント(特にCursor)でのSupabase SDK利用シナリオ精度向上 |
注目すべきは、全社ともGoogle SEO目的ではなく「開発者のIDEエージェント精度向上」を主目的として実装していることだ。この点がWEBコンテンツサイトとは文脈が異なる。
SEO文脈で注目されたのは2025年以降。Perplexityがllms.txtを参照しているという観測が広まり、「GEO施策の一環」として多くのWEBディレクターが実装に動いた。ここでGEOとAEOの定義を整理しておく。
| 概念 | 定義と対象エンジン | 2026年現在の有効性 |
|---|---|---|
| AEO Answer Engine Optimization |
FAQPage・HowTo構造化データで「ゼロクリック回答枠」に入る施策。主対象: Google FEATured Snippet / Bing AI Answers | Google公式ガイドで「JSON-LDの継続は推奨」。ただしchunking・専用マークアップは不要と明確化。 |
| GEO Generative Engine Optimization |
LLMが生成する回答に引用・言及されることを目的とした施策全般。主対象: Perplexity・ChatGPT・Claude・AI Overviews | Googleは「GEO専用ハックは不要」と宣言。ただし非コモディティコンテンツ・権威引用・一次体験は有効(エンジン共通)。 |
| 2026年の結論: AEO/GEO独自の「特化施策」は終焉。SEO基礎(E-E-A-T・構造化データ・一次体験コンテンツ)に統合される。ただしllms.txtはGeo以外の文脈(PerplexityBot・IDEエージェント)でまだ有意。 | ||
Google公式ガイドが出た日 ── 何が書いてあったか
Google Search Centralが2026年5月15日に公開した「Generative AI search optimization guide」は、2年間にわたってAEO(Answer Engine Optimization)・GEO(Generative Engine Optimization)の名のもとに乱立してきた「AI検索特化型施策」に対する、Googleの公式回答だ。
核心メッセージを原文で引用する。
"You don't need to crEATe new machine readable files, AI text files, markup, or Markdown to appear in Generative AI search."
(AI検索への表示のために、新しい機械可読ファイル・AIテキストファイル・マークアップ・Markdownを作成する必要はありません)
"From Google Search's perspective, optimizing for Generative AI search is optimizing for the search experience, and thus still SEO."
(Google検索の観点から見れば、生成AI検索に向けた最適化は検索体験への最適化であり、つまりSEOです)
25年以上のクロール経験を持つGooglebotは、テキストファイルのヒントがなくてもコンテンツを理解できる。AIサーチはRAG(Retrieval Augmented Generation)で動作し、従来の検索インデックスを根拠に回答を生成する。だから「SEO基礎を守っていれば、AI引用への追加施策は必要ない」というのがGoogleの立場だ。
Googleが「不要」と断言した5つのこと
ガイドでGoogleが明確に否定した施策を整理する。WEBディレクターの中には、これらを一生懸命やってきた人もいるはずだ。
① llms.txt / AI向けMarkdownファイル
「新しい機械可読ファイルは不要」と明言。John Mueller(Google Search Relations)は以前から「廃止されたキーワードメタタグの再来」と評していた。
② コンテンツのChunking(段落細分化)
「AIが理解しやすいように段落を細切れにする必要はない。1ページ内の複数トピックを処理できる」。Query Fanout技術の精度向上で、ページ単位ではなく段落単位での関連性判定が可能になっているため、細切れ化は逆効果になりうる。
③ AI専用の構造化データ
「GEO専用のSchema.orgマークアップは不要」。通常のJSON-LD(Article・FAQPage・HowToなど)で十分。ただし、SEO目的での構造化データ継続は推奨している。
④ AI意識した文体への書き換え
「Googleのシステムは同義語と文脈を理解する。特定の書き方に合わせる必要はない」。AI向けに書き直すほど、人間の読者にとってのコンテンツ品質が下がるケースが多い。
⑤ 不自然な「言及」の獲得工作
「スパム判定リスクがあり、思うほど有効ではない」。不正な手法でブランド言及を量産しても、品質システムとスパムフィルターが処理する。
この5点を一言でまとめると「AI検索特化型ハックは全部捨てろ、SEO基礎に戻れ」だ。Search Engine Journalはこれを「AEO/GEOのコテージ産業への終焉宣言」と評した。
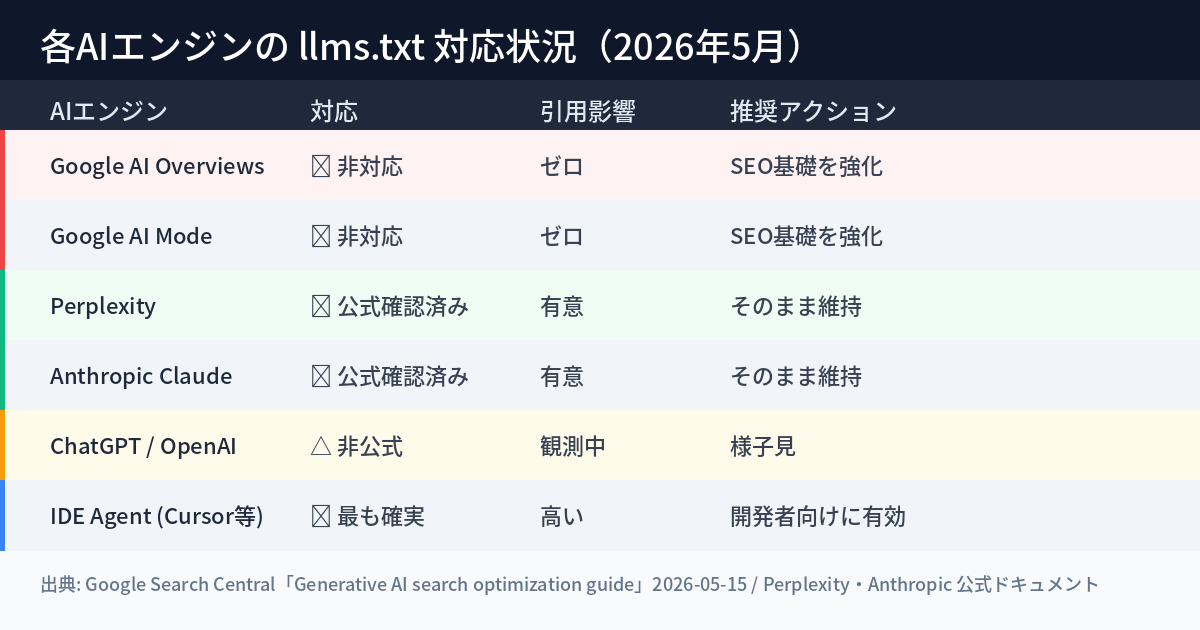
ただし「Google向け」に限定した話だ ── 見落とされている射程の問題
ここが重要だ。
UK在住のAI可視性研究者Mark McNeece(ai-visibility.org.uk)は、Googleの声明の「正確な射程距離」をこう分析した。
Googleが答えた質問は「llms.txtはGoogleのAI検索ランキングを助けるか?」という狭い問いだ。答えは明確に「いいえ」。
しかしGoogleが答えていない問いがある。「llms.txtはAIエコシステム全体で有用か?」——これはGoogleの管轄外なので沈黙した。
そして、ここに決定的な逆説がある。
Googleがllms.txtを不要と言った同じ日に、Anthropic・Cloudflare・Vercel・Stripe・Supabaseはそのllms.txtを自社サイトに置き続けている。
なぜか。Perplexity・Claude・ChatGPTという「Google以外のAIエンジン」が、llms.txtを参照しているからだ。
- Perplexity: PerplexityBotが定期的にllms.txtを取得し、クロール対象URLの優先順位付けに使用(公式確認済み)。User-Agentは「PerplexityBot」で識別可能で、robots.txtでのBot別制御が可能。Perplexity公式ドキュメントによれば、llms.txtのURLリストをインデックスの優先ヒントとして扱い、除外指定URLは引用候補から外す。更新されたサイトでは週次以上の間隔で再取得される。
- Anthropic(Claude): Claude Desktop・Claude.aiが取得ワークフローでllms.txtを尊重(公式確認済み)
- IDE Agent(Cursor・GitHub Copilot等): llms.txtを参照する最も確実な環境(開発者向けドキュメントサイトに特に有効)
- ChatGPT: 公式未確認だが観測レベルで相関あり
「Google向けには不要、AI全体向けには文脈次第」——これが2026年5月の正しい状況認識だ。
当サイトのLCRS実証データ ── Perplexityは引用している
理論ではなく、当サイトの実走データを見てほしい。
当サイトでは毎週「LCRS(LLM Citation Rate Score)」という独自指標を測定している。Google・ChatGPT・Perplexityなど各AIエンジンで特定クエリを検索し、当サイトが引用されているかを手動で確認する方式だ(LCRS 第10回測定レポート)。スコアの算出式は「引用されたクエリ数 ÷ 総テストクエリ数 × 100(%)」。測定クエリは「当サイトのコンテンツが答えるべき具体的な問い」を14〜18件選定し、週1回を基本に定点測定する。Aleyda Solisが2026年4月に定義した「Linked Citation Rate(LCR)」と定義が完全一致しており、業界標準語彙として名称も整合している。
第10回測定(2026年5月)の結果は15.9%(7/44クエリ)。その内訳が示唆に富む。
- Google AI Overviews: 引用 0件
- ChatGPT: 引用 1件(初引用、学習周期の遅延で限定的)
- Perplexity: 引用 6件(公開2〜5日後の記事を即座に引用)
当サイトはllms.txtを実装している(/llms.txt)。GA4のreferrerにはAI流入はほぼ映らないが(GA4 referrer 0 問題)、LCRS測定ではPerplexityの引用を毎週確認できる。
つまり当サイト自身が「Google向けには効果不明、Perplexity向けには有意」という分断を実証している。
Googleが「やれ」と言ったこと ── 非コモディティコンテンツへの回帰
Googleが不要なものを否定した一方で、推奨したことも明確だ。
最も繰り返し強調されたのが「非コモディティコンテンツ(Non-commodity content)」という概念だ。
ガイドはこう対比する。
コモディティ(AIに引用されない例):「7 Tips for First-Time Homebuyers」— 誰でも書ける一般情報
非コモディティ(AIに引用される例):「Why We Waived the Inspection and Saved Money」— 実際の体験に基づく、ほかでは得られない視点
研究データも後押しする。Princeton・Georgia Tech共同研究(GEO論文: AgGArwal et al., "GEO: Generative Engine Optimization", 2023, arXiv:2311.09735 — AI検索エンジンでのコンテンツ可視性向上を研究した先駆的論文)による効果測定では:
- 統計データを本文に追加: +41%の可視性向上
- 外部権威ソースの引用: +115%(低ランク記事での効果)
- 引用・出典の明示: +28%
- コンテンツ前半30%に直接回答を配置: LLM引用の44.2%がここから発生(前半30%は1,200字記事なら360字、2,000字なら600字が目安。同GEO論文のサンプル平均では「冒頭約300字に要旨を置く」形が最も引用率が高かった)
- 30日以内の鮮度更新: 3.2倍の引用獲得
また、Aleyda Solisが指摘した重要データがある。AI Overviewsの引用元の52%が上位50位以外のページから来ている(出典: BrightEdge Generative Parser™調査 / Aleyda Solis「Understanding Google AI Overviews: Citations, Rankings & Impact」2026年4月公開)。これは「従来SEOで上位にいれば自動的に引用される」という単純な話ではないことを意味する。コンテンツの質が順位を超えた判断基準になっている。
外部シグナルについても、バックリンクよりブランド言及の方がAI引用との相関が3倍高い(ブランド言及: 0.664 vs バックリンク: 0.218)。「被リンクを集める」から「業界メディアに言及される」へのシフトが求められている。

WEBディレクターへの処方箋 ── 今週のアクション5つ
理論を整理したところで、月曜朝から手を動かせる具体的なアクションに落とす。
① llms.txtを「軽量に整備して維持」する
Google向けには効果なし。しかしPerplexity・Claudeには有意なシグナル。削除するメリットはないが、維持コストを最小化した上で整備する。
最小限の実装手順(30分以内)
- ルートドメインに
llms.txtファイルを作成(例:https://example.com/llms.txt) - ファイル冒頭に「# サイト名」「> 1〜2文の概要」を記述
- AIに引用されたい代表的なページURL(Markdown形式)を10〜20件リストアップ
- サーバーにアップロード(Content-Type: text/plain; charset=utf-8)
- 動作確認:
curl -I https://example.com/llms.txtでHTTP 200を確認
Perplexity引用率を上げるための3施策
- 週次更新ページをllms.txtの最上位に置く: PerplexityBotは更新頻度の高いURLを優先クロールする特性がある。定期更新している記事・レポートページをリストの最初に置く
- データ・統計を含むページを重点リスト化: Perplexityは「ファクト引用」に強い。数値・調査結果・実測データを含むページほど引用候補になりやすい
- llms-full.txtで除外指定する: ログインページ・管理画面・個人情報関連ページを除外リストに入れてノイズを減らし、有益コンテンツへの誘導精度を高める
自動生成版(全URLを機械的に列挙したもの)は削除または代表的なページに絞り込む書き直しを推奨。
② 既存記事に統計データを追加する
+41%の可視性向上は施策別で最も手軽で効果が大きい。公式統計・研究数値・実測データを引用し、出典URLを明示する。当サイトのaddviewルーチンはまさにこれを毎日5件やっている。
③ 冒頭300字で問いに直接答える
LLMの引用の44.2%はコンテンツ前半30%から発生する。「結論を後に置く起承転結」より「冒頭で答えを出す逆ピラミッド型」の方がAI引用には有利だ。既存記事のリード文をチェックする価値がある。
④ 著者の専門性・実体験を明示する
E-E-A-Tの「Experience(実体験)」「Expertise(専門性)」をページ上で可視化する。著者ボックス・プロフィールリンク・「自サイトで実測した結果」などの一次体験の記述は、Googleが「非コモディティ」と呼ぶものの核心だ。BrightEdgeの調査では著者専門性の明示で+15%のオーガニック可視性向上が確認されている(2026年Q1)。
⑤ Perplexity向けのllms.txtを軽量に維持する(任意)
「Google不要」を聞いてすぐ削除しないこと。流入の9割がGoogle経由でも、1時間以内で実装できるPerplexity向けのシグナルを捨てる理由はない。当サイトの/llms.txtも継続維持する。
「Google向け不要」≠「AI全体で不要」 ── 2026年の正しい立ち位置
整理しよう。
Googleの2026年5月15日の発表は「AEO/GEOハックの終焉宣言」であり「SEO基礎への回帰宣言」だ。Google AI Overviews・AI Modeへの表示にllms.txtは効かない。これは公式に確定した。
しかし、AIエコシステムはGoogleだけではない。Googleの月間訪問数814億に対して、ChatGPTは51.4億(約6%)。AI Overviewsは全クエリの48%に表示され、ゼロクリック検索は69%に達している(2026年5月)。
この状況で「Google以外のAIエンジンからの引用を無視する」のは、攻めているとは言えない。
当サイトの選択はこうだ。
- Google向け: llms.txtに工数をかけず、非コモディティコンテンツ強化(addview・AI Ronブログ)に全振り
- Perplexity・Claude向け: llms.txtを手動で整理した形で維持(1時間以内の作業)
- 計測: LCRS週次測定で引用実績を把握し続ける(AI対応診断も活用)
「何をやめるか」を決めるのと同じくらい、「何を続けるか」の根拠を持つことが大切だ。
Googleが「不要」と言った。それを聞いて何もかも捨てる前に、誰向けの「不要」かを確認する。その1秒が、Perplexityからの引用を守ることになる。
迷えるWEBディレクターへ。Googleの言葉は正確に読む。そして、Googleだけがあなたの読者ではないことを、忘れないでほしい。
📌 関連コンテンツ
- LCRS 第10回測定レポート — ChatGPT初引用と15.9%の現在地
- GA4 referrer 0 とLCRS 10.7% ── AI検索時代に測るべき第4軸
- 毎日ルーチンをSKILL化して3サイトで並走させた日
- 検索がカートになる日 ── Google I/O 2026の3大発表
- LCRS 7回連続0%の現在地 ── それでも書き続ける理由
- SC数字異常 ── GSC 11ヶ月バグと3層計測OSの必要性
- AI Overview 91%正解の罠 ── 引用時CTR+35%の実測値
- Googleコアアップデート2025-2026全史
- 当サイトのllms.txt
- AI対応診断(無料ツール)